Couche 4 : La couche Transport
Nous avons vu jusqu'à maintenant, que nous sommes capables de faire dialoguer ensemble des machines d'un bout à l'autre d'Internet. Mais ce que nous voulons c'est pouvoir faire dialoguer une application cliente avec une application serveur. C'est là où la couche 4 entre en jeu, en ajoutant la notion d'application au réseau. C'est elle qui va faire le lien entre la couche applicative et les couches réseau.
Son rôle
Le rôle de la couche 4 est de gérer les connexions applicatives, c'est-à-dire de faire dialoguer ensemble des applications.
Son identifiant : le port
En couches 2 et 3, nous avions vu qu'il fallait une adresse pour identifier les éléments nécessaires à l'identification des moyens de communication. L'adresse MAC identifie la carte réseau en couche 2, et l'adresse IP identifie l'adresse de notre machine au sein d'un réseau, en couche 3. En couche 4, l'adresse utilisée est le port. Le port est une adresse, c'est même l'adresse d'une application sur une machine. Ainsi, nous pourrons identifier toute application qui tourne sur notre machine et qui a besoin de dialoguer sur le réseau. Si vous vous rappelez, dans la partie modèle client-serveur, j'avais montré que mon serveur MySQL était en écoute sur le numéro 3306.
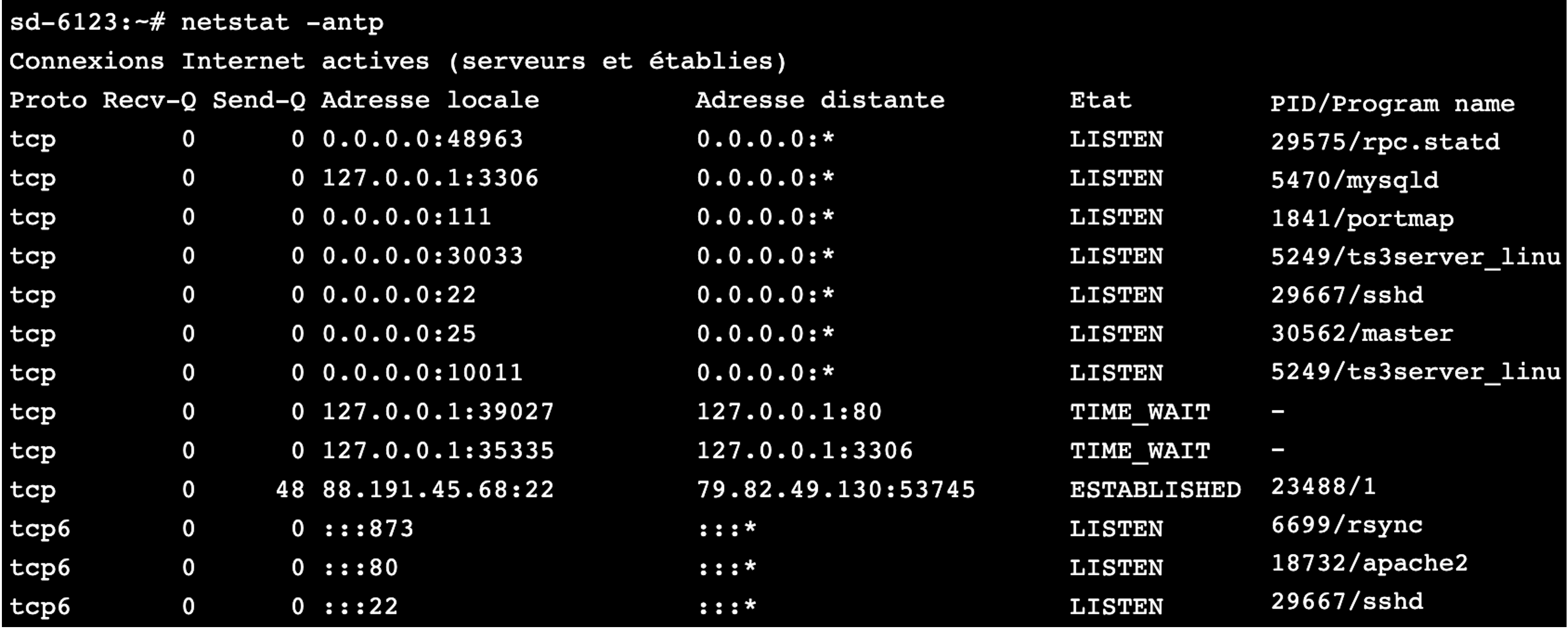
Nous savons maintenant que ce numéro est en fait le port d'écoute de l'application MySQL. Si je reçois une requête MySQL sur l'adresse IP 127.0.0.1 et sur le port 3306, le service MySQL va pouvoir répondre. Exemple de port en écoute
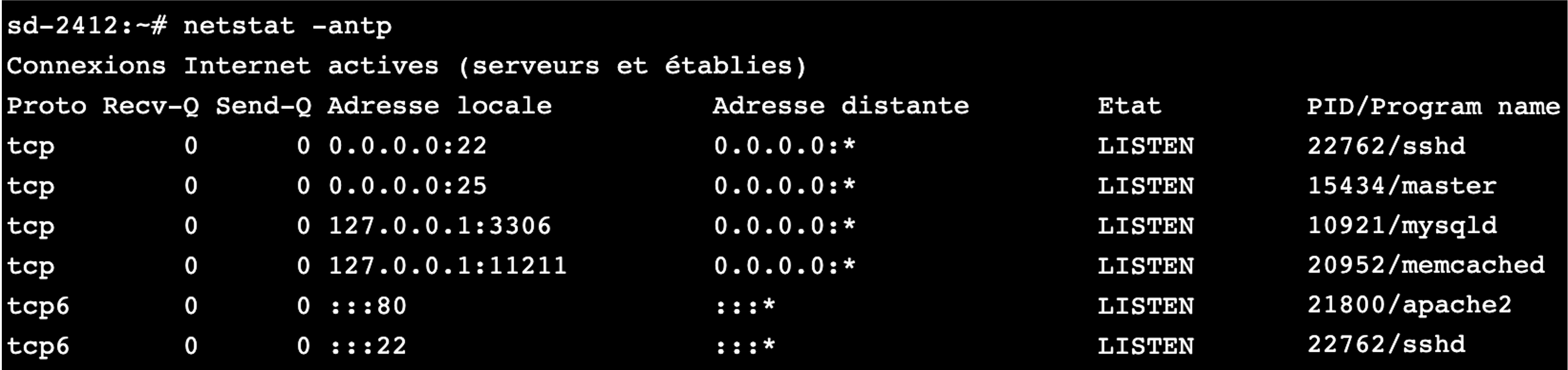
Nous voyons ici que le port 80 est en écoute à la ligne 5, et que c'est l'application apache2 qui est un serveur web. Le port 80 est le port utilisé pour les serveurs web. Nous pouvons donc nous douter qu'un serveur web est en écoute sur cette machine ! Il ne nous reste plus qu'à utiliser un client web, soit un simple navigateur, pour nous connecter à cette application. Essayez sur votre navigateur d'entrer https://163.172.38.160. Nous avons entré dans l'URL l'adresse IP 163.172.38.160, et nous avons été redirigés vers mon site www.lalitte.com. C'est normal, car cette adresse est celle de la machine qui héberge mon site. Un point important à remarquer est que nous n'avons pas indiqué que nous voulions atteindre le port 80, seule l'adresse IP a été indiquée. C'est normal, car notre navigateur, qui est un client web, fait toujours ses requêtes sur le port 80 si un port n'est pas spécifié. Toutefois, nous pouvons explicitement spécifier un port dans notre URL, par exemple le port 22 qui était en écoute aussi sur la machine. Dans ce cas, nous allons taper 163.172.38.160:22 dans l'URL pour préciser le port voulu. Firefox peut bloquer votre requête, car il considère que c'est une faille de sécurité que d'interroger un autre port que le port 80. Pour désactiver la protection, tapez about:config dans l'URL. Puis faites un clic droit dans la barre en haut sur la caseNom de l'option. Ajoutez une nouvelle chaîne de caractères network.security.ports.banned.override puis donnez-lui la valeur 1-65535. Vous pourrez maintenant indiquer le port que vous voudrez dans l'URL. Notez que cela ne fonctionnera pas sous Chrome. Vous avez donc le droit de changer de navigateur ! Nous voyons que nous tombons sur un serveur ssh. Ça tombe bien, car le port 22 est le port normalement réservé pour un serveur ssh.
Quelles adresses pour les ports ? Les ports sont codés en décimal sur deux octets. Ils peuvent donc prendre 2^16 valeurs, soit 65536 valeurs. Vu que l'on commence l'adressage des ports à 0, nous pourrons avoir des valeurs de ports de 0 à 65535. Donc nous pourrons faire tourner au maximum 65536 applications en réseau sur une machine. Cela devrait aller... mais on peut quand même parfois arriver à saturation, en cas d'attaque, quand quelqu'un envoie des tonnes de paquets sur nos différents ports pour nous saturer. Nous avons vu qu'un serveur web devait être sur le port 80. Y a-t-il d'autres ports réservés ? Oui, il y a quasiment autant de ports réservés que d'applications réseau qui existent.

Il y a donc 65535 ports réservés pour les applications ? Non, seule une partie d'entre eux sont réservés. D'ailleurs, historiquement, ce n'était que les ports inférieurs à 1024 qui étaient réservés. Mais aujourd'hui, beaucoup d'applications qui sortent utilisent des ports au-delà de 1024. À quoi peuvent bien servir les ports au-dessus de 1024 alors ? Nous avons dit que le port était l'adresse d'une application. Et nous avons vu que les ports étaient notamment utilisés pour les applications serveur, les services. Mais qu'en est-il des applications clientes ? Ont-elles aussi une adresse avec un port ? Les applications clientes ont des ports, elles aussi, mais ils ne sont pas réservés. Les ports attribués aux applications clientes sont donnés aléatoirement, au-dessus de 1024, par le système d'exploitation. Ce n'est pas gênant. Pour un serveur, vu qu'il est en écoute en permanence, il est important que l'on connaisse le port auquel on doit s'adresser. Pour un client, l'application ne va être en écoute que le temps de son fonctionnement. Ainsi, il peut être choisi au hasard tant que le système d'exploitation sait quelle application se trouve derrière quel port.
Deux protocoles, TCP et UDP
Pourquoi la couche 4 aurait-elle besoin de deux protocoles ? En fait, les personne qui ont créé les réseaux se sont rendu compte qu'il pouvait y avoir deux besoins différents pour le transport des données des applications :
- des applications qui nécessitent un transport fiable des données, mais qui n'ont pas de besoin particulier en ce qui concerne la vitesse de transmission ;
- des applications qui nécessitent un transport immédiat des informations, mais qui peuvent se permettre de perdre quelques informations.
La première catégorie regroupe une très grande majorité des applications d'Internet, car bon nombre d'entre elles ont besoin que chaque paquet émis soit reçu coûte que coûte ! Ce sont notamment les applications comme le web, la messagerie, le ssh, beaucoup de jeux en ligne, etc. Si un paquet est perdu, une page web ne pourra pas s'afficher correctement, ce sera pareil pour un mail, etc. La seconde catégorie regroupe moins d'applications, mais vous comprendrez vite pourquoi ces applications ont besoin d'être instantanées et peuvent se permettre qu'un paquet ne soit pas reçu. Il s'agit notamment des applications de streaming, comme la radio ou la télé sur Internet. Pour une radio en ligne, il est essentiel que les informations soient envoyées en temps réel, le plus rapidement possible. Par contre, si un ou plusieurs paquets sont perdus, on ne va pas arrêter la radio pour autant. L'utilisateur aura des coupures de connexion, mais la radio continuera d'émettre. On identifie donc ainsi deux besoins bien distincts l'un de l'autre :
- un protocole fiable mais sans nécessité de rapidité ;
- un protocole rapide sans nécessité de fiabilité.
C'est pour cela que nous avons deux protocoles pour la couche 4 : le protocole TCP et le protocole UDP. TCP est de la première catégorie, c'est un protocole extrêmement fiable. Chaque paquet envoyé doit être acquitté par le receveur, qui en réémettra un autre s'il ne reçoit pas d'accusé de réception. On dit alors que c'est un protocole connecté. Avec le protocole TCP, pour chaque information envoyée, on vérifiera que la machine en face l'a bien reçue. UDP, lui, est un protocole rapide, mais peu fiable. Les paquets sont envoyés dès que possible, mais on se fiche de savoir s'ils ont été reçus ou pas. On dit qu'UDP est un protocole non-connecté. Avec le protocole UDP, on envoie des informations, et ensuite, on prie très fort pour que celles-ci arrivent, mais on n'en sait rien.
Le protocole UDP
UDP (User Datagram Protocol) est le protocole le plus simple auquel vous aurez affaire en réseau. Étant donné que les objectifs associés à sa mise en œuvre sont la rapidité et la non-nécessité de savoir si une information est bien reçue, le format des messages envoyés sera très simple ! Le datagramme UDP On dit datagramme comme pour le message de couche 3 du protocole IP. C'est normal, car datagramme veut dire, en gros, message envoyé dont on ne sait rien sur la bonne transmission ou réception. Voici le contenu d'un datagramme UDP :

Datagramme UDP
Nous avons ici seulement 4 informations pour l'en-tête UDP. Chacune faisant 2 octets, cela nous fait un en-tête de seulement 8 octets ! C'est le plus petit en-tête que nous ayons vu, et que nous verrons. Étudions ces champs un par un.
- Pour le port source, c'est simple, c'est l'adresse de l'application qui envoie l'information.
- Pour le port destination, c'est l'adresse de l'application destinataire.
- Ensuite, il y a un champ de 2 octets qui représente la taille d'un datagramme, ce qui veut dire que la taille maximum d'un datagramme sera de 2^16 soit 65536 octets. Cependant, dans la réalité, il est très rare de voir des datagrammes UDP de plus de 512 octets. Ceci est notamment dû au fait que perdre un petit datagramme est acceptable, mais en perdre un gros est plus gênant, vu qu'UDP n'a pas de gestion des paquets perdus.
- Pour le checksum, ou CRC, le principe est le même que pour la couche 2 : s'assurer que les données reçues sont bien les mêmes que celles qui ont été transmises.
Pourquoi avoir un CRC pour le protocole UDP alors qu'il y en a déjà un pour la couche 2 avec le protocole Ethernet ? En effet, si vous avez bien compris le principe d'encapsulation, vous savez que le datagramme UDP est à l'intérieur de la trame Ethernet, et donc que le CRC de la trame vérifie les données de la couche 4 du protocole UDP. Pourquoi alors, faire ce CRC deux fois ? La réponse se trouve dans le modèle OSI. Si vous vous souvenez bien, une des règles associées au modèle OSI est que chaque couche est indépendante. Ainsi, ce n'est pas parce que la couche 2 avec le protocole Ethernet fait un CRC, que la couche 4 ne doit pas en faire, de même que la couche 3. Étant donné que chacune des couches n'est pas censée savoir qu'une autre couche fait un CRC, chacune implémente son propre CRC. D'ailleurs, Richard Stevens, l'auteur de la bible des réseaux, TCP/IP illustré, volume 1, a montré qu'il arrive parfois qu'un datagramme arrive en couche 4 avec des erreurs qui ont été produites entre le passage de la couche 3 à la couche 4. Comme quoi, cet acharnement de CRC n'est pas toujours inutile !
Les applications qui utilisent UDP Comme prévu, les applications de streaming vont, en énorme majorité, utiliser UDP, comme la radio sur Internet, la télé sur Internet, etc. On l'utilise aussi pour la téléphonie sur Internet, plus connue sous le nom de VoIP (Voice Over Internet Protocol) ou ToIP (Telephony Over IP). Mais on utilise aussi UDP pour transporter deux protocoles majeurs d'Internet que sont le DNS et le SNMP. Vous savez dès maintenant que ce sont deux exceptions qui utilisent UDP parmi la multitude d'applications qui utilisent TCP.
Le protocole TCP
Le principe de TCP (Transmission Control Protocol, protocole de contrôle de transmissions en français) est d'acquitter chaque octet d'information reçue. À l'inverse d'UDP, il y aura beaucoup d'informations dans l'en-tête TCP pour parvenir à suivre une connexion correctement. Mais nous n'allons pas tout de suite nous pencher dessus. Nous allons d'abord voir les principes de base de TCP. Avant de communiquer, on assure la communication. Prenons une conversation téléphonique. Avant de raconter son histoire, l'interlocuteur va d'abord s'assurer que son partenaire est bien présent au bout du fil. Cela donne:
- Alice appelle : Tut... tut...
- Bob répond : Allo ?
- Alice commence sa conversation : Allo, salut c'est Alice !
On voit très clairement ici qu'il faut établir la communication avant de parler du sujet. Il en sera de même en TCP. Les trois premiers paquets envoyés ne serviront qu'à établir la communication. Comme le allo, ce seront des paquets vides qui ne sont là que pour s'assurer que l'autre veut bien parler avec nous. TCP va utiliser des informations dans son en-tête pour dire si un paquet correspond à une demande de connexion ou si c'est un paquet normal.
Les drapeaux / flags Étant donné que les paquets qui vont être envoyés pour initialiser la connexion seront vides (ils ne contiendront pas de données) il faudra une information présente dans l'en-tête pour indiquer si c'est une demande de connexion, une réponse ou un acquittement (un acquittement sera une réponse vide qui servira simplement à dire à la machine en face que l'on a bien reçu ses informations, comme quand on dit "han han..." au téléphone pour bien spécifier que l'on écoute ce que dit notre interlocuteur). Pour cela, il va y avoir ce que l'on appelle des drapeaux (ou flags en anglais) dans l'en-tête TCP. Les drapeaux ne sont rien d'autre que des bits qui peuvent prendre la valeur 0 ou 1. Ainsi, il y aura dans l'en-tête TCP des bits qui vont indiquer quel est le type du message TCP envoyé.
Établissement de la connexion Le premier paquet sera une demande de synchronisation, comme le allo au téléphone, le flag correspondant est le flag SYN (SYN pour synchronized / synchronisation). Tous les flags sont connus sous leur forme courte, de trois lettres seulement. Ainsi, si je veux me connecter à une application serveur qui fonctionne avec TCP, je vais envoyer un paquet avec le flag SYN positionné pour lui indiquer que je veux dialoguer avec elle, c'est l'équivalent d'un "Tu veux bien dialoguer avec moi ?". Un serveur recevant une demande SYN doit normalement répondre qu'il est d'accord pour communiquer avec le client. Pour cela il va envoyer un ACK en réponse (ACK comme acquittement, ou acknowledgement en anglais). MAIS, il va, à son tour, demander si le client veut bien communiquer avec lui et positionner aussi le flag SYN dans sa réponse. Il y aura donc les flags SYN ET ACK positionnés dans sa réponse. Si le client a demandé à communiquer avec le serveur, pourquoi le serveur lui demande s'il veut bien communiquer avec lui ? La réponse à cette question est primordiale pour comprendre TCP. Quand on veut communiquer en TCP, on n'établit pas une, mais deux connexions. Car TCP considère qu'il va y avoir une communication dans un sens, et une communication dans l'autre sens. Il établit donc une connexion pour chaque sens de communication. Ainsi, quand le serveur répond à la requête SYN, il acquitte la demande avec le ACK, et fait une demande de connexion pour l'autre sens de communication, du serveur vers le client, en positionnant le flag SYN. La réponse a donc les flags SYN ET ACK positionnés. Toutefois, notre connexion n'est pas encore établie... Il faut encore que le client accepte la demande de connexion faite par le serveur. Le client va donc renvoyer un paquet avec un flag ACK. Cela donne le résultat que vous pouvez voir en figure suivante.
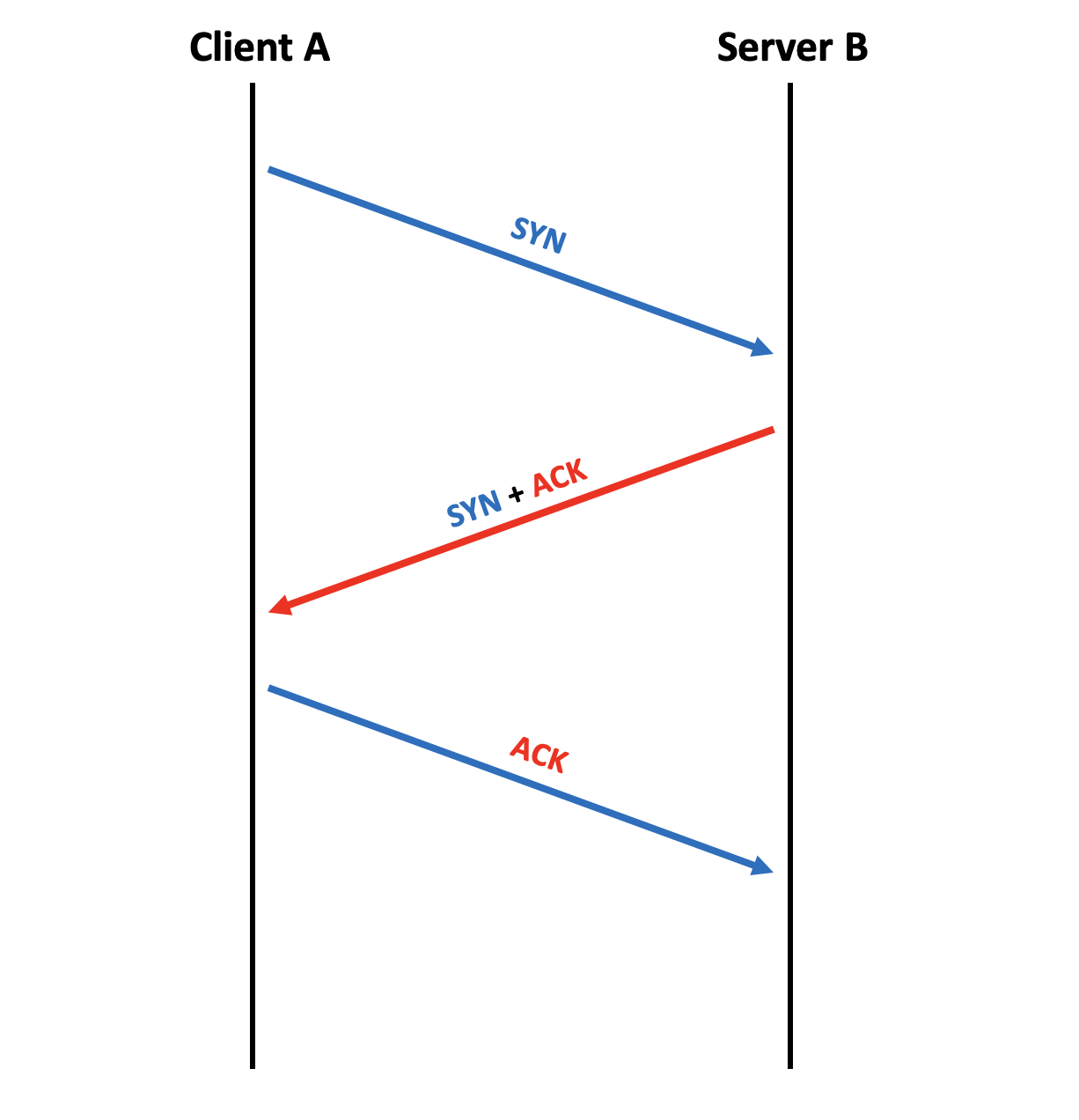
Three Way Handshake
Nous voyons bien ici la différence entre la communication bleue de A vers B et la communication rouge de B vers A. On voit d'ailleurs les couleurs des flags associés : en bleu, le premier SYN pour la demande de connexion de A vers B et le ACK dans la réponse pour acquitter la demande de connexion de A vers B ; en rouge le SYN pour la demande de connexion de B vers A et l'acquittement ACK dans le dernier paquet. L'établissement de la connexion TCP s'est donc fait par l'échange de trois paquets. C'est pour cela qu'on l'appelle Three Way Handshake ou poignée de main tripartite en français (mais tous les spécialistes utilisent le terme anglais, comme souvent en réseau).
Continuation de la connexion Maintenant que la communication est établie, les applications peuvent s'échanger des paquets autant qu'elles le veulent ! Le principe au niveau des flags est simplement d'avoir positionné le flag ACK. Donc tout paquet échangé après l'établissement de la connexion n'aura que le flag ACK de positionné. Presque, car nous n'avons vu que deux flags pour l'instant... Néanmoins, ce qui est sûr, c'est que le flag ACK sera positionné sur tous les paquets, pour acquitter la réception des paquets précédents. Voyez en figure suivante le schéma de la continuité d'une connexion.
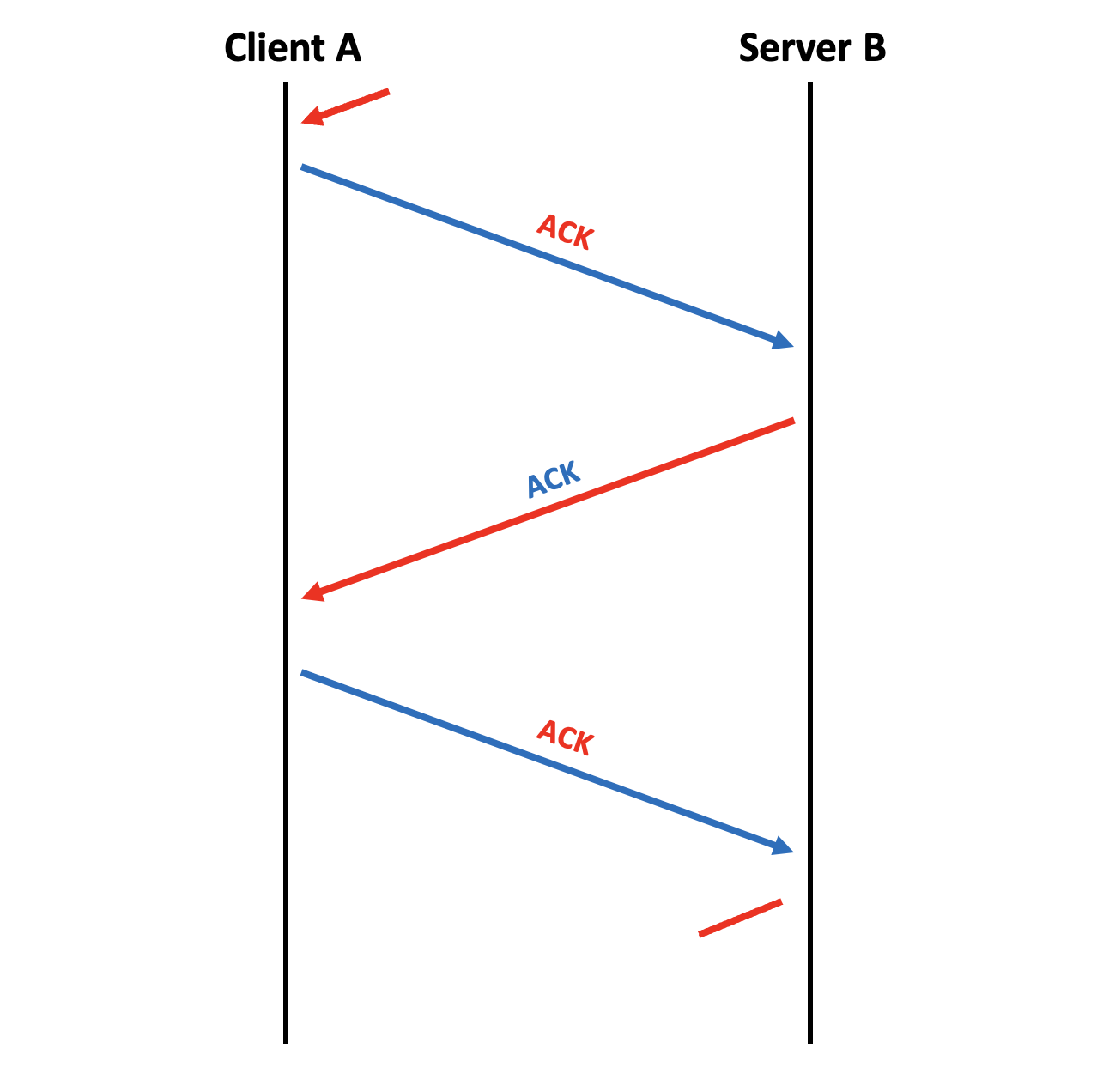
Continuité de la connexion
Fin de la connexion Une fois que les applications ont terminé leur communication, il faut encore fermer la connexion. On ne va pas laisser la connexion indéfiniment ouverte ! Si nous ne les libérions jamais, nos ports seraient rapidement tous utilisés. Donc, de la même façon que l'on a utilisé des paquets vides et des flags pour établir une connexion, nous allons faire de même pour la clôturer. Le flag que l'on va utiliser alors, à l'opposé de SYN, est le flag FIN (Finish). Imaginons que le client veuille fermer la connexion, il envoie donc un paquet avec le flag FIN positionné. Dès lors qu'une connexion est établie, tout paquet contiendra un flag ACK pour acquitter le paquet précédent. Donc lorsque l'on demandera la fermeture de la connexion avec le flag FIN, on en profitera pour acquitter le paquet précédent reçu en ajoutant aussi le flag ACK. La demande de fermeture contiendra donc les flags FIN et ACK. Le serveur pourra ensuite, lui aussi, demander la fermeture de la communication dans l'autre sens, et acquitter la réception de la demande de fin. Il placera donc, lui aussi, les flags FIN et ACK. Le serveur a demandé la fermeture de la communication dans le sens serveur -> client, mais le client ne lui a pas encore acquitté cette demande. Si jamais ce paquet était perdu, le serveur et le client continueraient à avoir leur connexion ouverte. Il faut donc que le client réponde au serveur qu'il a bien reçu sa demande de fermeture en envoyant un dernier paquet ACK. C'est seulement à ce moment que la connexion est fermée complètement et que les ressources des machines sont libérées (voir la figure suivante).
Terminaison de la connexion
Nous venons donc de voir comment se déroulait une connexion TCP : l'établissement à l'aide du three way handshake, la continuation et la fermeture. Il nous reste à voir les détails de l'en-tête TCP et notamment les flags dont nous avons parlé.
Le segment TCP Voici un nouveau terme pour nous : le segment TCP. Nous avions la trame Ethernet, le datagramme IP, le datagramme UDP, et nous avons maintenant le segment TCP. Nous n'allons pas encore représenter en détail toutes les informations de l'en-tête du segment TCP mais nous allons nous concentrer sur les éléments qui nous intéressent. Nous verrons par la suite le détail de celui-ci. Voici donc la bête:

Segment TCP
Nous pouvons voir qu'il reste encore quelques points d'interrogation, mais ne vous inquiétez pas, nous les détaillerons par la suite. L'en-tête fait 20 octets, comme celui de la couche 3. Faisons le détail de ce que nous pouvons voir.
- port source et port destination ;
- les flags, ils sont au nombre de 6 et nous en connaissons déjà 3 ;
- SYN
- ACK
- FIN
- RST
- PSH
- URG
- enfin, le checksum que nous connaissons aussi.
Il nous reste trois flags à expliciter, sachant que RST a une importance plus forte que les deux autres. En TCP chaque octet de données envoyé doit être acquitté. Si jamais il y a une incohérence entre les données envoyées et les données reçues, la connexion est considérée comme anormale et la machine qui s'en rend compte doit prévenir l'autre pour arrêter la connexion et en mettre en place une nouvelle. Cela se fait grâce au flag RST (Reset). Si deux machines A et B ont établi une connexion TCP et qu'après quelques échanges la machine A se rend compte qu'il y a une incohérence dans la connexion, elle va envoyer un paquet contenant le flag RST pour indiquer l'incohérence et demander à la machine B de clore la connexion. Donc pour une fois, la connexion ne sera pas terminée par la séquence FIN+ACK, FIN+ACK, ACK. De la même façon, si j'envoie un paquet SYN sur le port d'une machine qui est fermé, celle-ci doit me répondre RST pour me signifier que le port demandé n'est pas en écoute. Cette notion de réponse par RST pour un port fermé est importante, car nous nous en servirons quand nous voudrons scanner les ports ouverts sur une machine. Les flags PSH et URG peuvent être positionnés pour indiquer que le paquet doit être traité en priorité par la machine destinataire, mais nous ne détaillerons pas plus leur utilisation, car elle n'est pas nécessaire pour comprendre le fonctionnement des réseaux. Si vous souhaitez en savoir plus, je vous invite à jeter un coup d’œil au lien suivant :
Si vous faites des captures de paquets avec des outils de sniffers, type Wireshark, vous pouvez remarquer différents types de paquets échangés entre le client et le serveur du site. Ils peuvent être applicatifs, mais il y a aussi des paquets qui ne contiennent pas de données applicatives. On appelle ces paquets des paquets de signalisation. Ils servent à maintenir proprement la connexion entre les deux machines en indiquant en permanence à l'autre machine où nous en sommes de la connexion. C'est ce qui permet de garantir qu'aucune information ne sera perdue lors des échanges.