HTTP
L’Hypertext Transfer Protocol, généralement abrégé HTTP, littéralement « protocole de transfert hypertexte », est un protocole de communication client-serveur développé pour le World Wide Web. HTTPS (avec S pour secure, soit « sécurisé ») est la variante sécurisée par le chiffrement et l'authentification. HTTP est un protocole de la couche application dans le modèle OSI. Il peut fonctionner sur n'importe quelle connexion fiable. Dans les faits on utilise le protocole TCP comme couche de transport. Un serveur HTTP utilise alors par défaut le port 80 (443 pour HTTPS). Les clients HTTP les plus connus sont les navigateurs Web. HTTP a été inventé par Tim Berners-Lee avec les adresses Web et le langage HTML pour créer le World Wide Web. À cette époque, le File Transfer Protocol (FTP) était déjà disponible pour transférer des fichiers, mais il ne supportait pas la notion de format de données telle qu'introduite par Multipurpose Internet Mail Extensions (MIME). La première version de HTTP était très élémentaire, mais prévoyait déjà le support d'en-têtes MIME pour décrire les données transmises. Cette première version reste encore partiellement utilisable de nos jours, connue sous le nom de HTTP/0.9.
Implémentation
Méthodes Dans le protocole HTTP, une méthode est une commande spécifiant un type de requête, c'est-à-dire qu'elle demande au serveur d'effectuer une action. En général l'action concerne une ressource identifiée par l'URL (Uniform Resource Locator) qui suit le nom de la méthode. Dans l'illustration ci-dessous, une requête GET est envoyée pour récupérer la page d'accueil wikipedia :
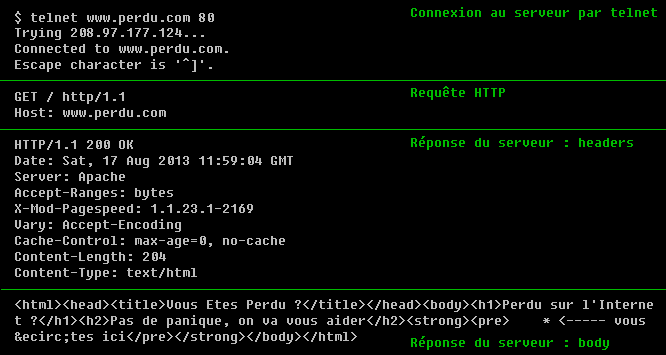
GET /wiki/Main_Page http/1.1
Host: en.wikipedia.orgIl existe de nombreuses méthodes, les plus courantes étant GET, HEAD et POST : GET C'est la méthode la plus courante pour demander une ressource. Une requête GET est sans effet sur la ressource, il doit être possible de répéter la requête sans effet. HEAD Cette méthode ne demande que des informations sur la ressource, sans demander la ressource elle-même. POST Cette méthode est utilisée pour transmettre des données en vue d'un traitement à une ressource (le plus souvent depuis un formulaire HTML). L'URI fourni est l'URI d'une ressource à laquelle s'appliqueront les données envoyées. Le résultat peut être la création de nouvelles ressources ou la modification de ressources existantes. À cause de la mauvaise implémentation des méthodes HTTP (pour Ajax) par certains navigateurs (et la norme HTML qui ne supporte que les méthodes GET et POST pour les formulaires), cette méthode est souvent utilisée en remplacement de la requête PUT, qui devrait être utilisée pour la mise à jour de ressources. (Définition de L'URI à la fin de la page) OPTIONS Cette méthode permet d'obtenir les options de communication d'une ressource ou du serveur en général. CONNECT Cette méthode permet d'utiliser un proxy comme un tunnel de communication. TRACE Cette méthode demande au serveur de retourner ce qu'il a reçu, dans le but de tester et effectuer un diagnostic sur la connexion. PUT Cette méthode permet de remplacer ou d'ajouter une ressource sur le serveur. L'URI fourni est celui de la ressource en question. PATCH Cette méthode permet, contrairement à PUT, de faire une modification partielle d'une ressource. DELETE Cette méthode permet de supprimer une ressource du serveur. Ces 3 dernières méthodes nécessitent généralement un accès privilégié. Du client au serveur La liaison entre le client et le serveur n'est pas toujours directe, il peut exister des machines intermédiaires servant de relais :
- Un proxy (ou serveur mandataire) peut modifier les réponses et requêtes qu'il reçoit et peut gérer un cache des ressources demandées.
- Une passerelle (ou gateway) est un intermédiaire modifiant le protocole utilisé.
- Un tunnel transmet les requêtes et les réponses sans aucune modification, ni mise en cache.
Versions
HTTP 0.9 Au début du World Wide Web, il était prévu d'ajouter au protocole HTTP des capacités de négociation de contenu, en s'inspirant notamment de MIME. En attendant, le protocole HTTP 0.9 était extrêmement simple.
- connexion du client HTTP
- envoi d'une requête de méthode GET
- réponse du serveur HTTP
- le serveur ferme la connexion pour signaler la fin de la réponse.
Requête :
GET /page.htmlLa méthode GET est la seule possible. Le serveur reconnaît qu'il a affaire à une requête HTTP 0.9 au fait que la version n'est pas précisée à la suite de l'URI. Réponse :
<TITLE>Exemple</TITLE>
<H1>Exemple</H1>Ceci est une page d'exemple.Pour répondre à une requête HTTP 0.9, le serveur envoie directement le contenu de la réponse, sans métadonnées. Il ne doit jamais se comporter ainsi pour les requêtes HTTP de version supérieure. Inutile de chercher les versions inférieures à 0.9 du protocole HTTP : elles n'existent pas, car HTTP 0.9 n'avait initialement pas de numéro de version. Il a fallu lui en attribuer un quand HTTP 1.0 est arrivé.
HTTP 1.0 Le protocole HTTP 1.0, décrit dans la RFC 1945, prévoit l'utilisation d'en-têtes spécifiés dans la RFC 822. La gestion de la connexion reste identique à HTTP 0.9 : le client établit la connexion, envoie une requête, le serveur répond et ferme immédiatement la connexion. Une requête HTTP présente le format suivant :
Ligne de commande (Commande, URL, Version de protocole)
En-tête de requête
[Ligne vide]
Corps de requêteLes réponses HTTP présentent le format suivant :
Ligne de statut (Version, Code-réponse, Texte-réponse)
En-tête de réponse
[Ligne vide]
Corps de réponseRequête :
GET /page.html HTTP/1.0
Host: example.com
Referer: http://example.com/
User-Agent: CERN-LineMode/2.15 libwww/2.17b3La version du protocole HTTP est précisée à la suite de l'URI. La requête doit être terminée par un double retour à la ligne (CRLFCRLF). HTTP 1.0 supporte aussi les méthodes HEAD et POST. On constate l'usage d'en-têtes inspirés de MIME pour transférer les métadonnées : Host Permet de préciser le site web concerné par la requête, ce qui est nécessaire pour un serveur hébergeant plusieurs sites à la même adresse IP (name based virtual host, hôte virtuel basé sur le nom). C'est le seul en-tête réellement important. Referer Indique l'URI du document qui a donné un lien sur la ressource demandée. Cet en-tête permet aux webmasters d'observer d'où viennent les visiteurs. User-Agent Indique le logiciel utilisé pour se connecter. Il s'agit généralement d'un navigateur web ou d'un robot d'indexation. Réponse :
HTTP/1.0 200 OK
Date: Fri, 31 Dec 1999 23:59:59 GMT
Server: Apache/0.8.4
Content-Type: text/html
Content-Length: 59
Expires: Sat, 01 Jan 2000 00:59:59 GMT
Last-modified: Fri, 09 Aug 1996 14:21:40 GMT
<TITLE>Exemple</TITLE>
<P>Ceci est une page d'exemple.</P>La première ligne donne le code de statut HTTP (200 dans ce cas).
Date Moment auquel le message est généré. Server Indique quel modèle de serveur HTTP répond à la requête. Content-Type Indique le type MIME de la ressource. Content-Length Indique la taille en octets de la ressource. Expires Indique le moment après lequel la ressource devrait être considérée obsolète ; permet aux navigateurs Web de déterminer jusqu'à quand garder la ressource en mémoire cache. Last-Modified Indique la date de dernière modification de la ressource demandée.
HTTP 1.1 Le protocole HTTP 1.1 est décrit par le RFC 2616 qui rend le RFC 2068 obsolète. La différence avec HTTP 1.0 est une meilleure gestion du cache. L'en-tête Host devient obligatoire dans les requêtes. Les soucis majeurs des deux premières versions du protocole HTTP sont d'une part le nombre important de connexions lors du chargement d'une page complexe (contenant beaucoup d'images ou d'animations) et d'autre part le temps d'ouverture d'une connexion entre client et serveur (l'établissement d'une connexion TCP prend un temps triple de la latence entre client et serveur). Des expérimentations de connexions persistantes ont cependant été effectuées avec HTTP 1.0 (notamment par l'emploi de l'en-tête Connection: Keep-Alive), mais cela n'a été définitivement mis au point qu'avec HTTP 1.1. Par défaut, HTTP 1.1 utilise des connexions persistantes, autrement dit la connexion n'est pas immédiatement fermée après une requête, mais reste disponible pour une nouvelle requête. On appelle souvent cette fonctionnalité keep-alive. Il est aussi permis à un client HTTP d'envoyer plusieurs requêtes sur la même connexion sans attendre les réponses. On appelle cette fonctionnalité pipelining. La persistance des connexions permet d'accélérer le chargement de pages contenant plusieurs ressources, tout en diminuant la charge du réseau. La gestion de la persistance d'une connexion est gérée par l'en-tête Connection. HTTP 1.1 supporte la négociation de contenu. Un client HTTP 1.1 peut accompagner la requête pour une ressource d'en-têtes indiquant quels sont les langues et formats de données préférés. Il s'agit des en-têtes dont le nom commence par Accept-. Les en-têtes supplémentaires supportés par HTTP 1.1 sont : Connection Cet en-tête peut être envoyé par le client ou le serveur et contient une liste de noms spécifiant les options à utiliser avec la connexion actuelle. Si une option possède des paramètres ceux-ci sont spécifiés par l'en-tête portant le même nom que l'option (Keep-Alive par exemple, pour spécifier le nombre maximum de requêtes par connexion). Le nom close est réservé pour spécifier que la connexion doit être fermée après traitement de la requête en cours. Accept Cet en-tête liste les types MIME de contenu acceptés par le client. Le caractère étoile * peut servir à spécifier tous les types / sous-types. Accept-Charset Spécifie les encodages de caractères acceptés. Accept-Language Spécifie les langues acceptées. L'ordre de préférence de chaque option (type, encodage ou langue) est spécifié par le paramètre optionnel q contenant une valeur décimale entre 0 (inacceptable) et 1 (acceptable) inclus (3 décimales maximum après la virgule), valant 1 par défaut. Le support des connexions persistantes doit également fonctionner dans les cas où la taille de la ressource n'est pas connue d'avance (ressource générée dynamiquement par le serveur, flux externe au serveur…). Pour cela, l'encodage de transfert nommé chunked permet de transmettre la ressource par morceaux consécutifs en précédant chacun par une ligne de texte donnant la taille de celui-ci en hexadécimal. Le transfert se termine alors par un morceau de taille nulle, où des en-têtes finaux peuvent être envoyés. Les en-têtes supplémentaires liés à cet encodage de transfert sont : Transfer-Encoding Spécifie l'encodage de transfert. La seule valeur définie par la spécification RFC 26163 est chunked. Trailer Liste tous les en-têtes figurant après le dernier morceau transféré. TE Envoyé par le client pour spécifier les encodages de contenu supportés (Content-Encoding, ne pas confondre avec Transfer-Encoding car chunked est obligatoirement supporté par les clients et serveurs implémentant le standard HTTP/1.1), et spécifie si le client supporte l'en-tête Trailer en ajoutant trailers à la liste.
HTTP/2 Une nouvelle version d'HTTP, HTTP/2, a été développée au sein du groupe de travail « Hypertext Transfer Protocol Bis » (httpbis) de l'Internet Engineering Task Force, et approuvée comme RFC standard le 18 février 2015. Le développement d'HTTP/2 a débuté à la suite de la création du protocole SPDY proposé par Google afin de réduire le temps de chargement des pages Web. Le groupe de travail httpbis s'était initialement interdit de proposer une nouvelle version d'HTTP, concentrant son activité sur la clarification des spécifications d'HTTP 1.1. Considérant l'arrivée de SPDY et son adoption rapide sur le Web, avec notamment des implémentations dans deux des principaux navigateurs Web, Google Chrome et Mozilla Firefox, Mark Nottingham, « chair » d'httpbis, a émis l'opinion qu'il était temps d'envisager HTTP/2 et proposé d'amender la charte d'httpbis en ce sens, initiant de fait le développement du nouveau protocole. Après plus de 2 ans de discussions, la RFC est approuvée en février 2015 par le groupe de pilotage de l'IETF, et est publiée en mai 2015.
HTTP/3 Une nouvelle version d’HTTP, HTTP/3, est la troisième et prochaine version majeure du protocole de transfert hypertexte utilisé pour échanger des informations sur le World Wide Web. Celle-ci repose sur le protocole QUIC (Quick UDP Internet Connections), développé par Google en 2012. La sémantique HTTP est cohérente d'une version à l'autre. En effet, les mêmes méthodes de requête, codes de statut et champs de message sont généralement applicables à toutes les versions. Si HTTP/1 et HTTP/2 utilisent tous deux TCP comme protocole de transport, HTTP/3 quant à lui utilise le protocole QUIC, un protocole de la couche transport qui est plus adapté au Web. Le passage à QUIC vise à résoudre un problème majeur de HTTP/2 appelé "Head-of-line Blocking" grâce à une encapsulation des paquets dans UDP. En effet, avec HTTP/2 reposant sur TCP, une connexion permet d'accéder aux ressources demandées une à une (une seule à la fois). Lorsque l'envoi d’une ressource est perturbé (par exemple par une perte de paquets), la livraison globale des ressources est ralentie. Avec HTTP/3 reposant sur le protocole QUIC, on n’a plus ce problème puisque tous les flux sont indépendants étant encapsulés dans UDP, protocole de transport ne nécessitant pas de connexion.
cURL Pour intérroger un serveur HTTP sur windows on peut utiliser la commande curl (cURL : abréviation de client URL request library : « bibliothèque de requêtes aux URL pour les clients » ou see URL : « voir URL ») destinée à récupérer le contenu d'une ressource accessible par un réseau informatique. La ressource est désignée à l'aide d'une URL et doit être d'un type supporté par le logiciel ($ curl -I www.example.org). Le logiciel permet également de créer ou modifier une ressource (contrairement à wget).
Bonus : URI Un URI, de l'anglais Uniform Resource Identifier, soit littéralement identifiant uniforme de ressource, est une courte chaîne de caractères identifiant une ressource sur un réseau (par exemple une ressource Web) physique ou abstraite, et dont la syntaxe respecte une norme d'Internet mise en place pour le World Wide Web (voir RFC 3986). La norme était précédemment connue sous le terme UDI. L'IETF l'a d'abord défini dans la RFC 2396 en se basant sur des propositions de Tim Berners-Lee (RFC 1630). Mise à jour par la RFC 2732 puis révisée de nombreuses fois sous le titre rfc2396bis, la RFC 3986 définit les URI en janvier 2005. Le sigle URI est généralement utilisé pour désigner une telle chaîne de caractères. Par exemple urn:ietf:rfc:2396 est un URI identifiant la RFC 2396. Les URI sont la technologie de base du World Wide Web car tous les hyperliens du Web sont exprimés sous forme d'URI. Principe Un URI doit permettre d'identifier une ressource de manière permanente, même si la ressource est déplacée ou supprimée. Application Bien que les URI soient très largement utilisés dans le monde informatique, avec surtout les URL sur Internet, on en retrouve d'autres applications dans le monde réel. Ainsi, le code ISBN, qui est l'identifiant unique d'un livre, permet de retrouver celui-ci depuis n'importe quelle librairie ou bibliothèque, dans le monde entier. On peut considérer également les codes-barres comme une métaphore d'URI dans le monde physique : un code-barres ne localise pas un produit, mais l'identifie (bien qu'il identifie l'ensemble des exemplaires d'un produit, pas chaque exemplaire individuellement, ce qui est le travail du numéro de série, lequel n'est pas systématique, mais réservé aux produits onéreux). Un URI peut être de type « locator » ou « name » ou les deux. Un Uniform Resource Locator (URL) est un URI qui, outre le fait qu'il identifie une ressource sur un réseau, fournit les moyens d'agir sur une ressource ou d'obtenir une représentation de la ressource en décrivant son mode d'accès primaire ou « emplacement » réseau. Par exemple, l'URL http://www.wikipedia.org/ est un URI qui identifie une ressource (page d'accueil Wikipédia) et implique qu'une représentation de cette ressource (une page HTML en caractères encodés) peut être obtenue via le protocole HTTP depuis un réseau hôte appelé www.wikipedia.org. Un Uniform Resource Name (URN) est un URI qui identifie une ressource par son nom dans un espace de noms. Un URN peut être employé pour parler d'une ressource sans que cela préjuge de son emplacement ou de la manière de la référencer. Par exemple, l'URN urn:isbn:0-395-36341-1 est un URI qui, étant un numéro de l'International Standard Book Number (ISBN), permet de faire référence à un livre, mais ne suggère ni où, ni comment en obtenir une copie réelle. Relation avec les URL et URN Le point de vue actuel du groupe de travail qui supervise les URI est que les termes URL et URN sont des aspects dépendant du contexte des URI, et que l'on a rarement besoin de faire la distinction entre les deux. Dans les publications techniques, spécialement les normes érigées par l'IETF et le W3C, le terme URL n'a pas été reconnu pendant longtemps, parce qu'il était rarement nécessaire de faire une distinction entre les URL et les URI. Cependant, dans des contextes non techniques et dans les logiciels du World Wide Web, le terme URL reste omniprésent. De plus, le terme adresse web, qui n'a pas de définition formelle, est souvent employé dans des publications non techniques comme synonyme d'URL ou URI, bien qu'il ne se réfère généralement qu'aux protocoles 'HTTP' et 'HTTPS'.