Active Directory, à plusieurs c’est mieux !

I - Les différents rôles : ADDS, ADFS, ADCS…
Quand vous passerez à la mise en place d’un Active Directory, lors de l’installation, vous verrez qu’il y a cinq rôles qui comprennent la notion d’Active Directory. Cependant, un seul d’entre eux est la base de tout et permet de mettre en place les services d’annuaire Active Directory. Ces cinq rôles permettent de répondre à des besoins différents, mais ils sont capables de fonctionner ensemble et de se « répartir les tâches », car ils sont conçus pour assumer un rôle bien spécifique.
1 - ADDS (Active Directory Domain Services)
Comme son nom l’indique, ADDS permet la mise en place des services de domaine Active Directory, autrement dit la mise en œuvre d’un domaine et d’un annuaire Active Directory. Ce rôle permet de gérer au sein d’un annuaire les utilisateurs, les ordinateurs, les groupes, etc. afin de proposer l’ouverture de session via des mécanismes d’authentification et le contrôle d’accès aux ressources. Enfin, je ne vous apprends rien, car depuis le début de ce cours on parle précisément de ce rôle, mais maintenant vous savez qu’il correspond au rôle « ADDS » défini dans Windows Server.
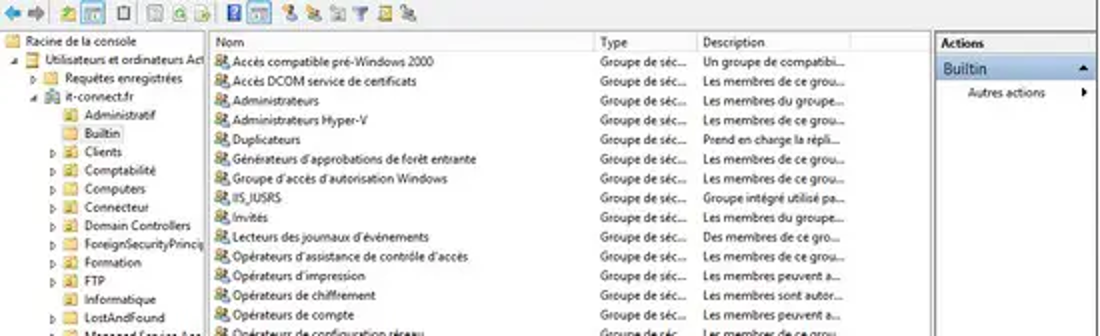
Console de gestion de l'Active Directory
2 - ADCS (Active Directory Certificate Services)
Ce rôle apporte une couche sécurité supplémentaire au sein du système d’information puisqu’il permet de gérer et de créer des clés ainsi que des certificats. Ce rôle est compatible avec de nombreuses applications, ce qui offre un intérêt supplémentaire à l’utiliser pour augmenter la sécurité de manière générale. ADCS est composé de différents modules qui permettent d’effectuer des demandes de certificats de diverses façons : par le web, par le réseau, etc.
3 - ADFS (Active Directory Federation Services)
Depuis Windows Server 2008, un rôle nommé « ADFS » est disponible. Il s’agit d’un service de fédération qui permet de simplifier l’accès à des applications, que l’on se trouve ou non sur le même réseau.
Principalement, ADFS permet l’intégration d’un mécanisme SSO (Single Sign-On) c’est-à-dire l’authentification unique. Je m’explique. On se connecte sur le portail ADFS avec ses identifiants, et si l’authentification réussit on obtient directement l’accès à l’application cible sans devoir se réauthentifier. Ainsi, les demandes d’authentification pour accéder aux applications sont centralisées et des jetons d’accès sont distribués aux clients, si l’accès est autorisé.
Exemple de portail ADFS
Bien sûr, ce rôle doit s’appuyer sur un annuaire Active Directory pour vérifier l’identité de l’utilisateur qui tente de se connecter.
4 - ADRMS (Active Directory Rights Management Services)
Depuis Windows Server 2008 R2, le rôle ADRMS est directement intégré au système d’exploitation. Il permet de gérer finement les autorisations sur les fichiers des utilisateurs. Il ne se limite pas aux simples autorisations comme « accès en lecture » ou « accès en lecture et écriture », ce sont plutôt des droits comme : « J’autorise les utilisateurs à sauvegarder le fichier, mais je n’autorise pas l’impression du fichier ». ADRMS est une application « client – serveur », cela implique qu’ADRMS s’intègre dans les applications pour créer de l’interaction. De ce fait, les applications doivent être compatibles, ce qui est le cas des versions de Microsoft Office Entreprise, Professional Plus et Integral. Finalement, ADRMS augmente la sécurité de vos fichiers au niveau des accès, ce qui permet de mieux protéger l’information.
5 - ADLDS (Active Directory Lightweight Directory Services)
Historiquement appelé « ADAM » pour un Active Directory en mode application, le rôle ADLDS se rapproche du mode ADDS classique à la différence qu’il n’implique pas la création d’un domaine, mais fonctionne directement en mode instance, où plusieurs instances d’ADLDS peuvent être exécutées sur le serveur. L’intérêt est de pouvoir créer un annuaire autonome qui permettra de créer une base d’utilisateurs, pouvant être utilisé dans le cadre d’un processus d’authentification auprès de l’annuaire LDAP. Par contre, ces utilisateurs ne peuvent pas être utilisés pour mettre en place du contrôle d’accès, car il n’y a pas cette notion de sécurité due à l’absence de contrôleur de domaine. ADLDS peut être utilisé pour créer un magasin d’authentification avec une base d’utilisateurs (comme des clients ou des prestataires externes) pour accéder à un portail web extranet, par exemple.
II - A la découverte du Catalogue Global
1 - Un catalogue global, c’est quoi ? Pour quoi ?
Le catalogue global est un contrôleur de domaine qui dispose d’une version étendue de l’annuaire Active Directory. En fait, comme tout contrôleur de domaine, il dispose d’une copie complète de l’annuaire Active Directory de son domaine, mais en supplément il dispose de :
- Un répliqua partiel pour tous les attributs contenus dans tous les domaines de la forêt
- Toutes les informations sur les objets de la forêt
Le catalogue global est un annuaire qui regroupe des éléments provenant de l’ensemble de la forêt, c’est en quelque sorte un annuaire central. On le différencie d’un contrôleur de domaine standard, car en temps normal, chaque contrôleur de domaine contient une copie de l’annuaire de son domaine. Quant au catalogue global, il contient une copie des attributs principaux de tous les domaines de la forêt. Ainsi, un contrôleur de domaine « catalogue global » sera capable de localiser des objets dans l’ensemble de la forêt, car il a une vue d’ensemble sur tous les objets. Les contrôleurs de domaine classique s’appuieront sur lui pour justement localiser des objets dans une forêt. Exemple : Il y a trois domaines : Domaine A, Domaine B, Domaine C. Deux contrôleurs de domaine se trouvent au sein du domaine A, un contrôleur de domaine « standard » et un second qui dispose du rôle de « catalogue global ». Conclusion :
- Le contrôleur de domaine standard disposera de la partition d’annuaire du domaine A
- Le contrôleur de domaine catalogue global dispose des partitions d’annuaire du domaine A, mais aussi du domaine B et du domaine C
Les attributs du schéma qui doivent être répliqués sont identifiés par la valeur « Partial Attribute Set » définie dans l’Active Directory. Microsoft définit par défaut cette politique de réplication de façon à prendre les attributs les plus utilisés dans une recherche, mais elle peut être personnalisée.
2 - Qui est catalogue global ? Est-il tout seul ?
Le premier contrôleur de domaine créé au sein d’une forêt est automatiquement catalogue global. Autrement dit, lorsque vous montez un Active Directory, vous créez automatiquement un nouveau domaine dans une nouvelle forêt, ce qui implique que le contrôleur de domaine soit catalogue global. Par ailleurs, il est fortement recommandé de définir au minimum deux contrôleurs en tant que catalogue global. Tout simplement pour assurer la disponibilité du rôle et répartir la charge au niveau des requêtes.
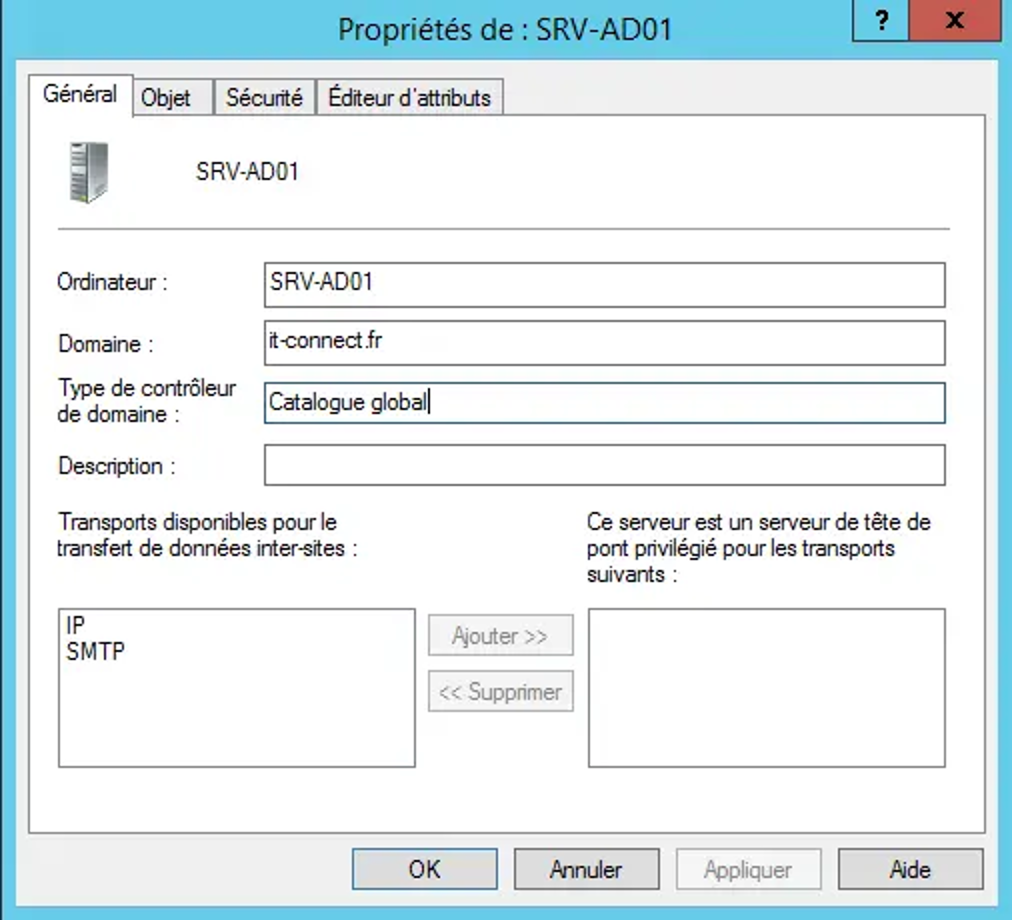
Affichage de la propriété "Catalogue Global"
a. Cas d’une forêt mono-domaine
Il est recommandé d’activer le rôle de catalogue global sur l’ensemble des contrôleurs de domaine du domaine. En effet, l’impact sera faible sur les performances systèmes dans ce type de configuration, mais ça permettra d’assurer la redondance du service. Le catalogue global est essentiel à la localisation des objets, et c’est encore plus vrai lorsqu’il y a plusieurs domaines, mais aussi au bon fonctionnement de certaines applications.
b. Cas d’une forêt multi-domaines
Lorsqu’il y a plusieurs domaines au sein d’une forêt, il y aura surement des emplacements géographiques différents. Notamment si l’entreprise dispose de plusieurs sites, cela implique d’étendre le réseau à différents endroits. Ainsi, le réseau se doit d’être hautement disponible pour que le contrôleur de domaine d’un site A soit sûr de pouvoir contacter un catalogue global situé sur un site B. Par exemple, cela pourrait empêcher la connexion d’un utilisateur si la liaison est rompue, car le contrôleur de domaine ne pourra pas récupérer les informations auprès du catalogue global. Une alternative serait d’activer l’option de « mise en cache de l’appartenance aux groupes universels » sur un site distant, pour limiter le trafic réseau grâce à la mise en cache des informations. La règle suivante est donnée par Microsoft : « Définir un catalogue global (au minimum) sur un site lorsqu’il y a une centaine d’utilisateurs ». C’est intéressant pour éviter d’être pénalisé par une liaison lente entre deux sites, puisque plus il y a d’utilisateurs, plus il y aura de demandes. Cas spécifique : certaines applications sont gourmandes et communiquent beaucoup avec le catalogue global, par exemple Microsoft Exchange. Dans ce cas-là, positionnez un catalogue global proche pour avoir de bonnes performances. En résumé, il faut positionner avec stratégie les contrôleurs de domaine « catalogue global » mais vous pouvez aussi opter pour une option simple : activer le rôle sur tous les contrôleurs de domaine de la forêt.
3 - Les quatre fonctions clés du catalogue global
Le catalogue global assure quatre fonctions clés auprès du système Active Directory et pour « venir en aide » aux autres contrôleurs de domaine de la forêt, à savoir :

Le catalogue global est un point central dans un environnement où il y a plusieurs domaines, puisqu’il doit faire le lien entre tous les objets de tous les domaines de la forêt. Lorsqu’il n’y a qu’un seul domaine dans la forêt, le catalogue global perd tout son intérêt, car les autres contrôleurs de domaine sauront « se débrouiller seul ».
III - Les cinq rôles FSMO
Depuis Windows Server 2000, Microsoft a intégré la notion de rôle FSMO au sein d’un environnement Active Directory. On dénombre cinq rôles FSMO différents, ayant chacun un objectif précis. Pour votre information, FSMO signifie « Flexible Single Master Operation ».
1 - Les rôles FSMO, ça sert à quoi ?
Lorsque l’on met en place un environnement Active Directory, il y a de très fortes chances (car c’est conseillé) que l’on ait plusieurs contrôleurs de domaine. De ce fait, tous les contrôleurs de domaine « normaux » disposent d’un accès en écriture sur l’annuaire. Cependant, certaines tâches sont plus sensibles que d’autres, et il serait dangereux d’autoriser la modification de certaines données sur deux contrôleurs de domaine différents, en même temps. De ce fait et pour minimiser les risques de conflits, Microsoft a décidé d’implémenter les rôles FSMO qui permettent de limiter la modification de certaines données internes à l’annuaire Active Directory. Au sein d’un environnement, on attribuera la notion de « rôle FSMO » à « maître d’opération ». En fait, le maitre d’opération est le contrôleur de domaine qui détient un ou plusieurs rôles FSMO. Détenir un rôle signifie pour un contrôleur de domaine qu’il est capable de « réaliser une action particulière au sein de l’annuaire ». Il est à noter qu’il ne peut pas y avoir plusieurs maîtres d’opérations pour le même rôle FSMO, au sein d’un domaine ou d’une forêt (selon le rôle concerné). Voici les cinq rôles que nous allons étudier :

2 - Rôle « Maître d’attribution des noms de domaine »
Le maître d’opération qui détient ce rôle est unique au sein de la forêt, et il est le seul autorisé à distribuer des noms de domaine aux contrôleurs de domaine, lors de la création d’un nouveau domaine. De ce fait, il est notamment utilisé lors de la création d’un nouveau domaine. Le contrôleur de domaine à l’initiative de la création doit impérativement être en mesure de contacter le contrôleur de domaine disposant du rôle FSMO « Maître d’attribution des noms de domaine » sinon la procédure échouera. Enfin, je tiens à préciser qu’il a également pour mission de renommer les noms de domaine. En résumé, il est unique au sein d’une forêt et attribue les noms de domaine.
3 - Rôle « Contrôleur de schéma »
Pour rappel, le schéma désigne la structure de l’annuaire Active Directory, le schéma est donc un élément critique au sein de l’environnement Active Directory. Cela implique l’unicité au sein de la forêt de ce maître d’opération, qui sera le seul – contrôleur de domaine – à pouvoir initier des changements au niveau de la structure de l’annuaire (schéma). En fait, comme le schéma est unique, son gestionnaire est unique également. En résumé, il est unique au sein d’une forêt et gère la structure du schéma.
4 - Rôle « Maître RID »
Comme vous le savez déjà, les objets créés au sein de l’annuaire Active Directory dispose de plusieurs identifiants uniques. Parmi eux, il y a notamment le GUID et le DistinguishedName mais aussi l’identifiant de sécurité « SID », c’est ce dernier qui nous intéresse dans le cadre du maître RID. - Pourquoi RID ? Le RID est un identifiant relatif qui est unique au sein de chaque SID, afin d’être sûr d’avoir un SID unique pour chaque objet de l’annuaire. Le SID étant constitué d’une partie commune qui correspond au domaine, le RID est essentiel pour rendre unique chaque SID. C’est là que le maître RID intervient... Unique au sein d’un domaine, ce maître d’opération devra allouer des blocs d’identificateurs relatifs à chaque contrôleur de domaine du domaine. Ainsi, chaque contrôleur de domaine aura un bloc (pool) de RID unique qu’il pourra attribuer aux futurs objets créés dans l’annuaire. Bien sûr, tous les contrôleurs de domaine ne vont pas épuiser le pool de RID au même rythme… Un contrôleur de domaine qui atteindra un certain niveau d’épuisement de son stock de RID disponible contactera le Maître RID pour en obtenir des nouveaux. Cela implique que la création d’un objet est impossible si le Maître RID du domaine n’est pas disponible. En résumé, il est unique au sein d’un domaine et attribue des blocs de RID aux contrôleurs de domaine pour assurer que les SID des objets soient unique.
5 - Rôle « Maître d’infrastructure »
Unique au sein d’un domaine, le contrôleur de domaine qui dispose du rôle de Maître d’infrastructure a pour objectif de gérer les références entre plusieurs objets. Prenons un exemple pour mieux comprendre ce que cela signifie. Imaginons qu’un utilisateur d’un domaine A soit ajouté au sein d’un groupe du domaine B. Le contrôleur de domaine « Maître d’infrastructure » deviendra responsable de cette référence et devra s’assurer de la réplication de cette information sur tous les contrôleurs de domaine du domaine. Ces références d’objets sont également appelées « objets fantômes » et permettent au contrôleur de domaine de faciliter les liens entre les différents objets. Un objet fantôme contiendra peu d’information au sujet de l’objet auquel il fait référence (DN, SID et GUID). Dans le cas de l’exemple ci-dessus, un objet fantôme sera créé sur le domaine B afin de faire référence à l’utilisateur du domaine A. De ce fait, si l’objet est modifié ou supprimé à l’avenir, le Maître d’infrastructure devra se charger de déclencher la mise à jour de l’objet fantôme auprès des autres contrôleurs de domaine. En quelque sorte, il accélère les processus de réplication et la communication entre les contrôleurs de domaine. En résumé, il est unique au sein d’un domaine et doit gérer les références d’objets au sein du domaine.
6 - Rôle « Émulateur PDC »
L’émulateur PDC (Primary Domain Controller) est unique au sein d’un domaine et se doit d’assurer cinq missions principales :
- Modification des stratégies de groupe du domaine (éviter les conflits et les écrasements)
- Synchroniser les horloges sur tous les contrôleurs de domaine (heure et date)
- Gérer le verrouillage des comptes
- Changer les mots de passe
- Assure la compatibilité avec les contrôleurs de domaine Windows NT
En résumé, il est unique au sein d’un domaine et assure diverses missions liées à la sécurité et par défaut il joue le rôle de serveur de temps pour l’ensemble du domaine.
7 - La gestion des maîtres d’opération
Par défaut, le premier contrôleur de domaine du domaine détient les cinq rôles FSMO, par faute de choix. Cependant, il est possible de transférer les rôles si vous souhaitez les répartir entre plusieurs contrôleurs de domaine, il y a une véritable flexibilité à ce niveau-là. Pour transférer un rôle d’un contrôleur de domaine vers un autre, on pourra utiliser l’interface graphique de Windows ou encore l’utilitaire « ntdsutil ». Je vais maintenant répondre à une question qui a dû vous venir à l’esprit : « Comment faire si le contrôleur de domaine qui dispose d’un ou plusieurs rôles est corrompu ? ». Rassurez-vous, tout n’est pas perdu. En effet, il faudra réaliser une opération de « seizing » qui consiste en fait à forcer la récupération d’un ou de plusieurs rôles, ce qui sera d’une utilité cruciale en cas de corruption d’un contrôleur de domaine. Là encore, on pourra procéder via l’utilitaire « ntdsutil ».
IV - Les relations d’approbations
Une relation d’approbation est un lien de confiance (Trust Relationship) établie entre deux domaines Active Directory, voir même entre deux forêts Active Directory. Ces relations permettront de faciliter l’accès aux ressources entre les domaines concernés, ce qui permet de mutualiser les accès bien que les domaines disposent d’une base de données Active Directory différente. On crée les relations d’approbations par l’intermédiaire de la console « Domaines et approbations » intégrée à Windows Server.
1 - Cas d’utilisation des relations d’approbations
Les relations d’approbations peuvent s’avérer utiles et sont utilisées dans plusieurs cas de figure :
- Une entreprise dispose de plusieurs filiales avec des noms différents, donc des domaines différents, elle pourra créer des relations de confiance entre ses domaines
- Une multinationale, qui scindera son infrastructure en plusieurs domaines, on peut imaginer un par zone géographique (Europe, Asie, Amérique, etc), il faudra là aussi créer des relations de confiance pour faciliter l’accès aux ressources.
- La fusion de deux entreprises existantes, qui utilisent à la base chacune leur domaine. La relation d’approbation permettra de faciliter la fusion au niveau du système d’information (avant une éventuelle restructuration complète)
- Etc.
2 - Direction et transitivité
Lorsque l’on parle de relations d’approbations, on ne peut pas échapper à la notion de direction et de transitivité, il va falloir s’y faire. Définissons ces termes : - Direction Dans le cadre d’une relation d’approbation, la direction peut être unidirectionnelle c’est-à-dire uniquement dans un sens, ou bidirectionnelle c’est-à-dire dans les deux sens. Qu’est-ce que cela signifie ? Une relation d’approbation unidirectionnelle signifie qu’un domaine A approuve un domaine B, sans que l’inverse soit appliqué. De ce fait, un utilisateur du domaine B pourra accéder aux ressources du domaine A, alors que l’inverse ne sera pas possible ! Pour que cela soit possible, il faut que la relation d’approbation soit bidirectionnelle pour que les deux domaines s’approuvent mutuellement. Un utilisateur du domaine A pourra alors accéder aux ressources du domaine B, et inversement. - Transitivité Une relation d’approbation, en plus d’être unidirectionnelle ou bidirectionnelle, peut être ou ne pas être transitive. La transitivité signifie que si un domaine A approuve un domaine B, et que ce domaine B approuve un domaine C, alors le domaine A approuvera implicitement le domaine C. Autrement dit, « comme A approuve B et que B approuve C, alors A approuve C ». Attention tout de même, cette transitivité se limite aux relations d’approbations entre les domaines, et non entre les forêts.
3 - Les approbations prédéfinies
Les approbations prédéfinies sont des relations d’approbations créées automatiquement lorsque l’on étend une forêt ou un domaine. J’entends par là le fait d’ajouter un domaine enfant à un domaine existant, par exemple. Si l’on dispose d’un domaine « it-connect.local » et que l’on ajoute le domaine enfant « paris.it-connect.local », il y aura automatiquement une relation de confiance entre ces deux domaines. Une relation d’approbation transitive et bidirectionnelle sera créée entre ces deux domaines. On parlera d’approbation « parent/enfant ».
4 - Les approbations externes
Il est possible de réaliser des relations d’approbations externes, c’est-à-dire entre des domaines situés dans des forêts différentes. Ces relations sont unidirectionnelles et non transitives. Pour que l’approbation soit réciproque, il faut que chaque domaine effectue une relation vers le domaine cible, ce qui permettra d’arriver indirectement à une relation bidirectionnelle. Avec une relation d’approbation externe, on donne l’accès uniquement au domaine depuis lequel la relation est établie. Voici un exemple :
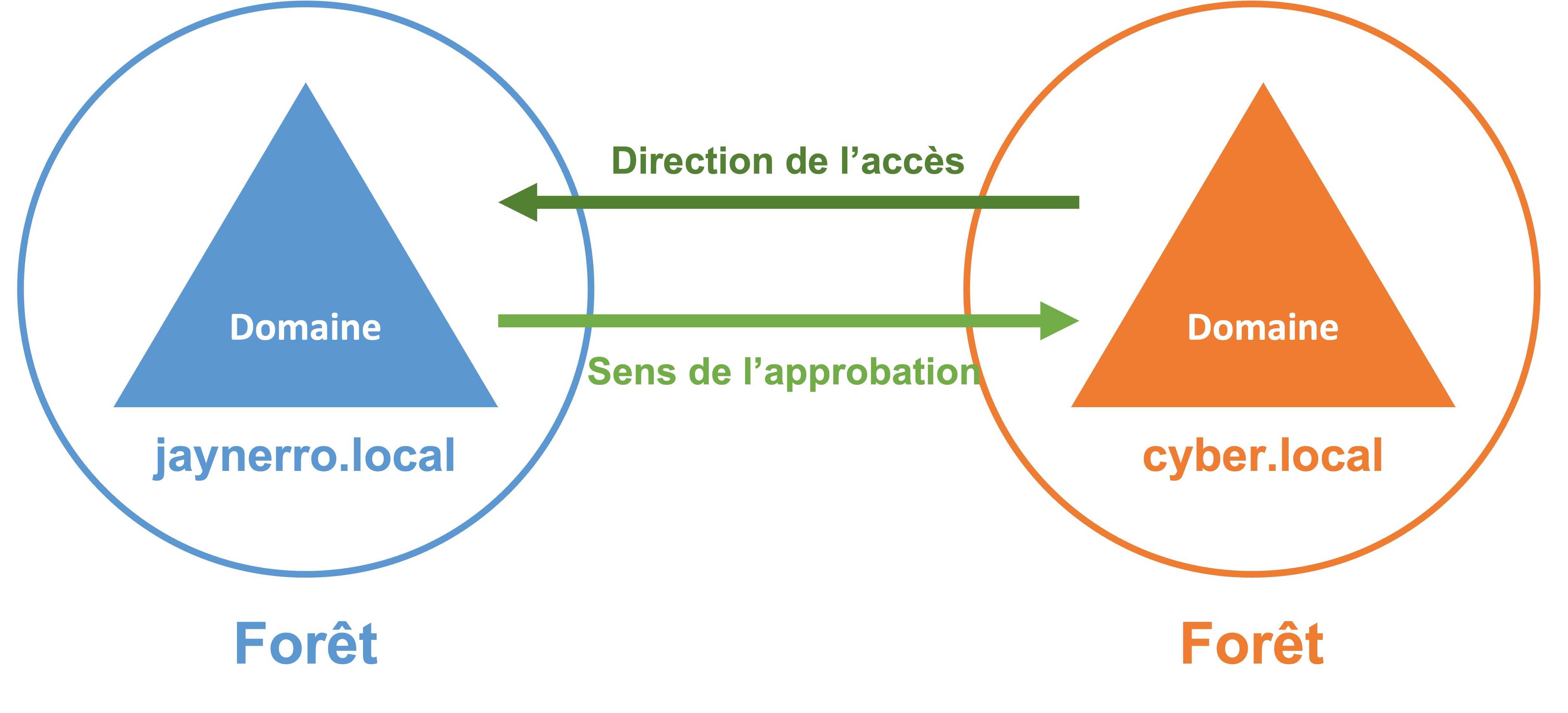
5 - Conclusion
Qu’il s’agisse des relations d’approbations créées automatiquement ou de celles que vous créerez manuellement, elles jouent un rôle important dans l’accès aux ressources. Une arborescence de domaine bien organisée facilitera la mise en place des relations d’approbations, ce qui simplifiera la vie aussi bien aux utilisateurs qu’aux administrateurs, puisque l’accès aux ressources sera plus « libre » et l’administration plus flexible. Il est important de noter qu’avec les relations d’approbations, l’étendue d’un compte utilisateur est agrandie, c’est-à-dire qu’il peut être utilisé au-delà du domaine auquel il appartient. De ce fait, la sécurité doit être pointilleuse sur l’ensemble des domaines et de l’infrastructure, pour ne pas laisser une porte ouverte sur un domaine et qui permettrait d’accéder à un autre domaine. Ces relations d’approbations évitent également la nécessité de créer des comptes en doublons sur plusieurs domaines, puisqu’un seul compte utilisateur pourra être utilisé pour accéder aux ressources de plusieurs domaines. Dans un environnement multidomaine, la mutualisation devient encore plus forte grâce à ces liens de confiance interdomaines.
V - Le partage SYSVOL et la réplication
1 - Le partage SYSVOL
Lorsqu’un contrôleur de domaine est installé, de nombreux éléments sont installés et créés sur le serveur, le partage SYSVOL en fait parti.
a. Introduction à SYSVOL
Stocké à l’emplacement « C:\Windows\SYSVOL », « SYSVOL » signifie « System Volume », et il sert à stocker des données spécifiques qui doivent être répliquées entre les contrôleurs de domaine ou accessibles par les ordinateurs clients. Plus précisément, voici les éléments principaux que l’on trouvera dans le partage SYSVOL :

Pour rappel, les scripts de connexion s’exécutent à l’ouverture de session de l’utilisateur, ils sont généralement écrits en BATCH et comporte des commandes qui permettent de créer des lecteurs réseau sur les machines clientes (commande « net use »). Quant aux stratégies de groupe, elles sont récupérées par les clients puis appliquées, dans le but d’appliquer une stratégie de personnalisation de l’espace de travail de l’utilisateur. De ce fait, si le partage SYSVOL est en erreur, vous aurez de gros problèmes ! Plus de réplication des GPOs et scripts de connexion entre les contrôleurs de domaine, plus possible pour les clients de récupérer les dernières mises à jour de GPO et les scripts… Bref, vous imaginez la galère… D’où l’intérêt de prendre connaissance de l’existence du partage SYSVOL. Attention, certaines personnes utilisent ce partage pour stocker toutes sortes de données, ce n’est pas du tout recommandé ! Non seulement, car le partage SYSVOL n’est pas fait pour ça, mais aussi, car les processus de réplication seront plus longs (plus de données à répliquer).
b. Réplication de SYSVOL
Le dossier SYSVOL est répliqué entre les différents contrôleurs de domaine, pour que le contenu soit identique, et que les clients bénéficient tous des mêmes données (à jour). Sur les anciennes versions de Windows Server, notamment Windows Server 2000 et Windows Server 2003, le mécanisme FRS (File Replication Service) était utilisé pour la réplication. Depuis Windows Server 2008, FRS est mis de côté pour laisser la place à DFSR (Distributed File System Replication), qui est plus fiable et plus performant.
c. La structure de SYSVOL
Le répertoire « C:\Windows\SYSVOL\ » est composé de plusieurs sous-dossiers :
- domain : ce répertoire contient toutes les données à jour (GPO et scripts), réparties en deux sous dossiers : « Policies » et « scripts ».
- Policies : ce répertoire est stocké sous « domain » et stocke toutes les GPOs du domaine, que l’on crée au sein de la console « Gestion des stratégies de groupe ». Un sous-dossier par GPO est créé où le nom du dossier correspond au GUID de l’objet GPO.
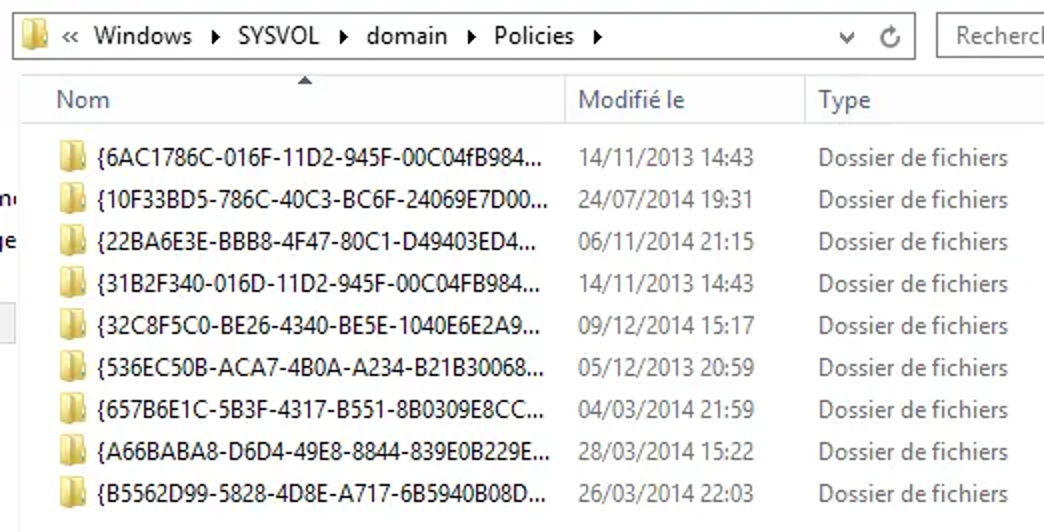
Répertoire "Policies" stocké dans SYSVOL
- scripts : ce répertoire est stocké sous « domain » et contient les différents scripts, notamment les scripts de connexion.
- staging : ce répertoire est utilisé pour créer une file d’attente (queue) des données en attente de réplication à destination des autres contrôleurs de domaine.
2 - Réplication : Quoi ? Quand ? Comment ?
Qui dit redondance, dit nécessité de répliquer les données afin que les données soient identiques sur les différents membres. C’est le même principe pour les contrôleurs de domaine, puisqu’ils doivent se répliquer pour mettre à jour différentes choses : - Base annuaire Active Directory Si un utilisateur est créé, modifié ou supprimé, il faut synchroniser les changements auprès des autres contrôleurs de domaine. De la même manière, si l’on intègre un nouvel ordinateur dans le domaine, cela créera un objet « ordinateur » dans l’annuaire, il est donc nécessaire de synchroniser ce changement. Le protocole RPC over IP (Remote Procedures Call over Internet Protocol) est utilisé pour répliquer la base d’annuaire. - Les stratégies de groupes et les scripts Une nouvelle stratégie de groupe créée, un paramètre modifié dans une GPO existante, ou encore la suppression d’une GPO, sont autant d’opérations qui impliquent un changement et donc la nécessité de répliquer des données. - DNS Comme nous l’avons vu dans un module précédent, le DNS joue un rôle important dans une architecture Active Directory. Pour assurer la continuité de service, on utilise au moins deux serveurs DNS. Ceci implique que les enregistrements des zones soient répliqués entre les serveurs DNS, pour que les informations retournées soient identiques. Imaginez si un serveur DNS n’est pas à jour et qu’il retourne une mauvaise adresse IP à une requête client, cela générera des problèmes de communication au sein de l’infrastructure. Maintenant, vous savez ce qui doit être répliqué et pourquoi ça doit être répliqué, mais alors quand est-ce la réplication se déclenche ? - Délai de réplication Il y a un temps de latence de 5 minutes (par défaut) entre le moment où vous effectuez la modification, et le moment où le contrôleur de domaine source va notifier un autre contrôleur de domaine qu’il a effectué une modification. Ensuite, s’il y a un second contrôleur de domaine à notifier, il y aura un intervalle de 30 secondes entre chaque réplication, pour éviter de surcharger le contrôleur de domaine source.
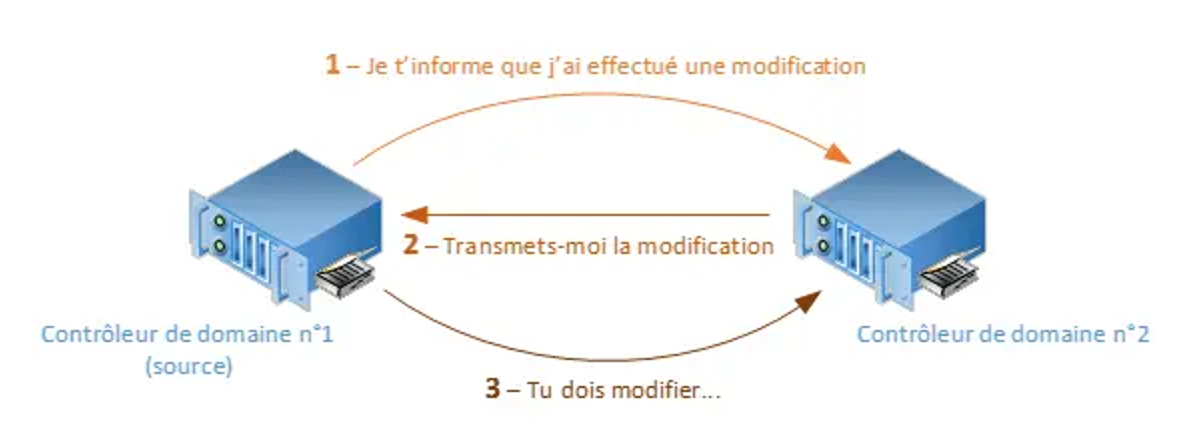
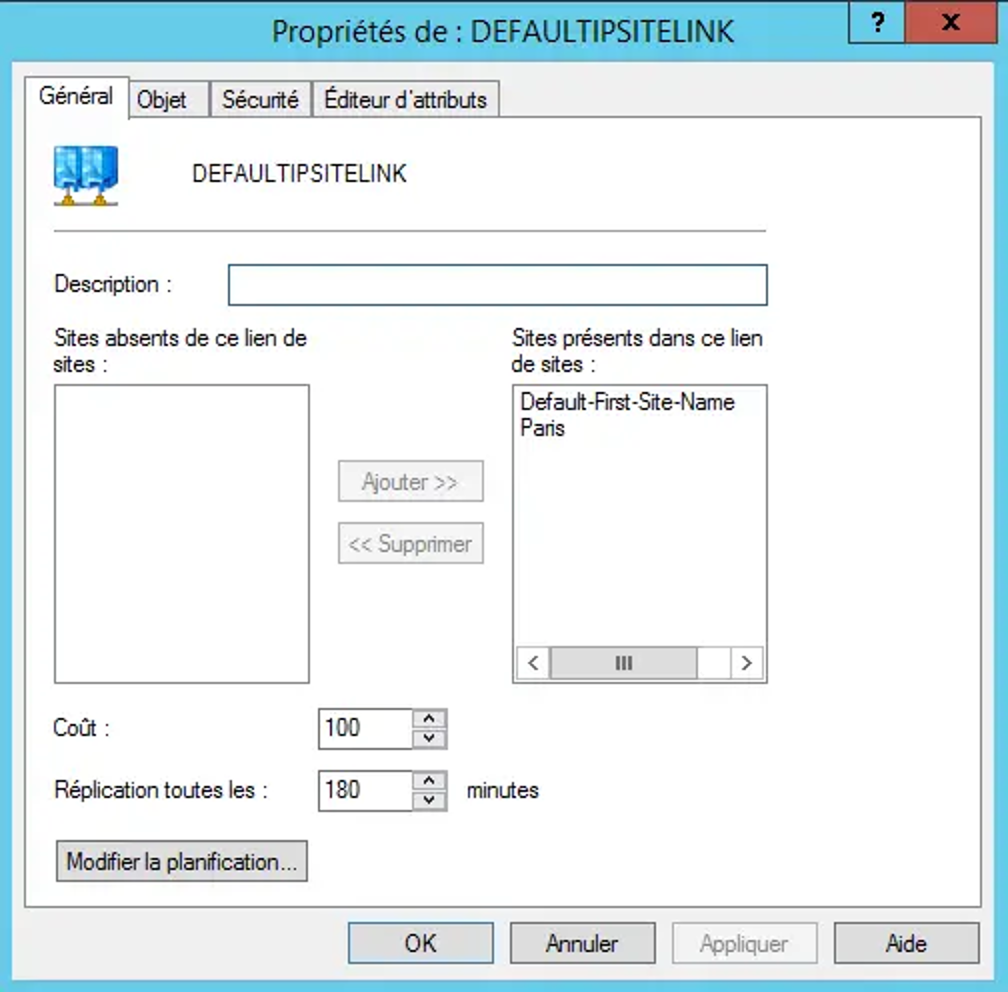
Cependant, il existe des cas de « réplication urgente » où l’on n’observera aucune latence. C’est le cas par exemple lorsqu’on désactive un utilisateur, change un mot de passe … Et de toute action liée à la sécurité. Imaginons maintenant qu’aucune modification ne soit effectuée pendant une heure, ce qui a des chances d’arriver, car on ne passe pas son temps à modifier les données de l’annuaire… Un processus de réplication est automatiquement déclenché pour contrôler que tout est bien à jour. - Méthode de réplication La réplication avec le protocole RPC over IP est sûre, mais le contenu n’est pas compressé, ce qui répond plus à un fonctionnement de réplication intrasite. En fait le contenu est chiffré et les connexions authentifiées grâce au protocole Kerberos. Lorsque l’infrastructure est répartie sur plusieurs sites distants, le protocole utilisé pour la réplication dépendra de la vitesse de connexion, mais la plupart du temps il s’agira toujours du RPC. À la différence de la réplication intrasite, le trafic RPC généré lors d’une réplication intersites est compressé, ce qui permet d’économiser de la bande passante, mais nécessite des ressources CPU pour décompresser le contenu. Dans certains cas, où la liaison intersites serait lente et avec un temps de latence fort, il est possible d’utiliser le protocole SMTP pour la réplication (Oui, oui, le SMTP, le protocole pour envoyer des mails). Cependant, il n’est pas en mesure de répliquer le répertoire « SYSVOL », il peut seulement répliquer des éléments précis : mises à jour du schéma, la configuration ou encore les données du catalogue global. Vous l’aurez compris, le protocole RPC over IP est au cœur de la réplication entre les contrôleurs de domaine, aussi bien en intrasites qu’en intersites. Le SMTP joue un rôle secondaire pour des réplications spécifiques sur des liaisons lentes, comme une liaison satellite, et il ne peut être utilisé que pour des contrôleurs se trouvant dans des domaines différents. - Déclarez vos sites Les services Active Directory économisent la bande passante entre les sites, en réduisant au minimum la fréquence de réplication. De plus, on peut planifier la disponibilité des liens intersites pour la réplication. Par défaut, la réplication intersites a lieu toutes les 3 heures sur chaque lien intersites. Lorsque l’on dispose de nombreux sites, il y a des chances pour que les liaisons ne soient pas toutes de la même qualité. De ce fait, il pourra être nécessaire de répliquer moins souvent sur les liaisons lentes que sur les liaisons rapides. Pour que l’Active Directory comprenne comment est organisée votre infrastructure de manière géographique. Il faut déclarer ses différents sites dans la console « Sites et services Active Directory », puis créer des liens entre les sites ainsi qu’indiquer les adresses réseau utilisées sur ces sites. Ainsi, on ajoutera nos différents sites, et dans ces sites on ajoutera des serveurs. Cela permettra de dire : « Sur le site Paris, j’ai le contrôleur de domaine nommé SRV-AD02 » et « Sur le site Rennes, j’ai le contrôleur de domaine nommé SRV-AD03 ». De plus, une notion de coût est intégrée pour chaque lien intersites. Ajustez sa valeur selon la vitesse, l’efficacité et la fiabilité de la liaison. Ainsi, si plusieurs liens connectent les mêmes sites, alors pour la réplication le lien ayant le coût le plus faible sera choisi. Le second lien faisant office de backup pour le mécanisme de réplication (cela n’empêche pas que ce lien soit utilisé pour autre chose).
Enfin, il faut savoir que la réplication entre les contrôleurs de domaine est automatiquement générée par le vérificateur de cohérence des connaissances (KCC - Knowledge Consistency Checker). Le KCC fonctionne sur tous les contrôleurs de domaine et c’est lui qui génère la topologie de réplication de la forêt .