Protégez et surveillez votre environnement

I - Protégez votre parc informatique
1 - Mettez le parc à jour
Dans un parc informatique, le manque de suivi des mises à jour permet régulièrement à des attaquants de prendre la main sur une ou plusieurs machines. Des vulnérabilités sur des systèmes d’exploitation ou des applications sont dévoilées tous les jours, et des correctifs sont alors publiés par les éditeurs pour protéger leurs clients. D’ailleurs, Windows publie tous les deuxièmes mardis de chaque mois les derniers patchs de sécurité. C’est ce qui est appelé le Patch Tuesday. Pour plus d’informations sur les patchs de sécurité proposés par Microsoft, vous pouvez vous tourner vers sa documentation, ou vers le site Ultimate Windows Security. Mais alors, comment concrètement mettre à jour mes systèmes, mes applications, et suivre le niveau de mise à jour global du parc en permanence ? Pour la partie système d’exploitation, en environnement Active Directory, vous allez devoir mettre à jour Windows sur les postes de travail et les serveurs. Pour cela, la solution WSUS (Windows Server Update Service) proposée par Microsoft est très adaptée. Elle vous permettra de télécharger les mises à jour de Microsoft une et une seule fois sur le serveur de mise à jour WSUS, et ensuite de les distribuer à tous les postes Windows. Outre les systèmes d’exploitation, il y a de grandes chances pour que des applications soient déployées dans votre parc. Il est également crucial que ces applications soient maintenues à jour. Différents outils existent pour détecter les versions des logiciels installés, et proposer des mises à jour si besoin. Parfois même, les outils intègrent une liste des vulnérabilités existantes, et comparent les versions des logiciels installés sur les différents postes pour détecter s’ils sont vulnérables ou non. Un outil français répond à ce besoin : CyberWatch ; mais c’est un outil payant. En plus des mises à jour, quelques éléments doivent être également contrôlés sur un parc. Lorsque des applications sont installées, il arrive régulièrement que le compte permettant de les administrer soit un compte par défaut avec un mot de passe par défaut. Vous savez, ces fameux comptes “admin:admin”, ou “admin.password”. Ces comptes doivent absolument être modifiés. Idéalement, si l’application le permet, l’authentification multifacteur devrait être activée pour les applications critiques, au minimum.
2 - Cloisonnez le réseau
Vous vous souvenez des phases de reconnaissance avec les scans réseau, ou des techniques de mouvement latéral pour compromettre de nouveaux comptes et de nouveaux postes ? Le cloisonnement du réseau peut permettre de réduire nettement les risques associés à ces attaques. En effet, si un attaquant compromet un poste utilisateur, mais dont les accès réseau sont limités au strict minimum, alors son périmètre d’attaque sera réduit. Une idée d’architecture réseau limitant les possibilités d’un attaquant pourrait être la suivante. Vous divisez votre parc informatique en 3 zones :
- Postes utilisateurs ;
- Serveurs ;
- Postes d’administration.
D’un point de vue réseau, vous n’autorisez que certains flux, et refusez tous les autres. C’est bien plus efficace que d’interdire des flux spécifiques. Parmi les flux que vous autorisez, il y aura ceux permettant aux postes de travail de se connecter aux applications. Ce sont donc des flux allant de la zone utilisateurs à la zone serveurs. Par exemple, vous pourrez ajouter le protocole SMB des utilisateurs vers les serveurs de fichiers, ou encore HTTP vers les applications web. Il n’y a en revanche aucune raison d’autoriser RDP dans la grande majorité des cas, ou encore les flux entre les postes utilisateurs. Vous devrez également autoriser les flux depuis la zone d’administration vers les autres zones, mais uniquement dans ce sens. Aucun flux ne doit pouvoir aller vers les postes d’administration. Quand vous avez découvert les scans réseau, vous vous êtes bien rendu compte que c’était une vision du système d’information depuis un endroit donné. Eh bien, depuis les postes utilisateurs ou les serveurs, la zone d’administration doit être invisible. Aucun scan ne doit pouvoir détecter la présence de cette zone. Si c’est effectivement en place, cette zone sera vraiment protégée. Bien entendu, il existe toujours des exceptions à mettre en place. Il arrive que des serveurs aient besoin de contacter des postes de travail, pour pousser des mises à jour, par exemple. Mais une bonne règle à retenir, c’est que par défaut, aucun flux ne doit passer. Il faut ajouter les flux autorisés au fil de l’eau, ce qui vous permettra de vraiment maîtriser votre matrice des flux, et limitera énormément les possibilités d’un attaquant. Pensez d’ailleurs à bien documenter et tracer ces exceptions, pour ne pas faire un empilement de règles dont on oublie rapidement les raisons d’existence.
3 - Archivez les données
En mettant en place des mesures de sécurité sur votre parc, vous diminuez le risque de compromission. Mais ce risque n’est jamais nul. Vous avez sans doute entendu parler des attaques de type rançongiciel ou ransomware. Ce sont des logiciels malveillants qui ont pour but de chiffrer l’ensemble des machines d’un parc informatique, et qui demandent ensuite de l’argent contre la clé de déchiffrement. Payer la rançon n’est pas une solution pérenne. D’une part parce qu’il arrive régulièrement qu’après avoir payé, la clé ne soit pas envoyée, ou que le logiciel de déchiffrement ne soit pas fonctionnel. D’autre part parce que si les acteurs malveillants ont réussi à chiffrer votre parc une fois, ils pourront revenir plus tard et recommencer. C’est pourquoi il est crucial de sauvegarder et d’archiver correctement ses données de façon régulière, pour pouvoir repartir sur une base récente et saine en cas de compromission. Ainsi, la première étape consiste à activer la sauvegarde (ou backup) des serveurs. Vous n’êtes peut-être pas obligé de tous les sauvegarder, mais certains sont nécessaires, comme les contrôleurs de domaine (ou du moins le contrôleur de domaine principal) et les serveurs de fichiers. La fonctionnalité Sauvegarde Windows Server proposée par Microsoft sur les serveurs permet d’automatiser ce processus. Les étapes d’installation et de configuration sont présentées sur le site RDR-IT. Attention cependant à la destination des sauvegardes. Il y a des entreprises qui archivent très régulièrement tous leurs serveurs, mais qui enregistrent les sauvegardes sur un serveur qui faisait lui-même partie du domaine Active Directory. Lorsque l’attaquant compromet tout le domaine, il a également compromis le serveur de backup. Tous les serveurs peuvent être alors chiffrés, incluant les sauvegardes des serveurs. Pour cette raison, il est important que les sauvegardes soient stockées à plusieurs endroits, dont au moins une destination hors ligne. Ces dernières ne doivent pas être accessibles depuis le réseau de l’entreprise, pour éviter ce type de conséquence. Plusieurs possibilités existent, comme le stockage physique sur bande, par exemple. Vous pouvez également externaliser les sauvegardes chez un fournisseur cloud, comme Azure. Une fois que vous avez mis en place la sauvegarde dans un endroit sûr, c’est un très bon début, mais ça ne sert à rien si vous n’arrivez pas à les utiliser en cas de problème. Vous devez donc absolument tester la restauration de vos serveurs à partir des sauvegardes, et ce régulièrement. En effet, les solutions de sauvegarde, les flux autorisés, les versions des OS évoluent, donc les processus que vous avez mis en place peuvent évoluer.
4 - Durcissez les postes
Enfin, quoiqu’il arrive, les postes de travail et les serveurs doivent être absolument surveillés et durcis. En effet, quand un attaquant souhaite compromettre un réseau, il exécutera des actions malveillantes sur les machines. Ces actions devraient être bloquées, et détectées immédiatement par les équipes de défense.
Vous devez alors avoir sur tous les postes et serveurs une solution EDR (Endpoint Detection & Response), qui est la version améliorée d’un antivirus. C’est un outil qui d’une part surveille le poste sur lequel il est installé. Il analyse les comportements suspects en suivant des règles. Par exemple, s’il détecte qu’une console cmd.exe a été exécutée par le processus word.exe, ça peut être un comportement malveillant. Ces actions peuvent être signalées, voire bloquées. C’est un antivirus à qui on peut donner de l’intelligence. Pour pouvoir faire ça, il a également l’avantage d’enregistrer ce qu’il se passe sur le poste. Le jour où un poste est détecté comme compromis, l’historique des actions enregistrées par l’EDR permettra aux équipes de défense d’analyser le comportement malveillant et de le bloquer sur le reste de l’entreprise, par exemple. Il est également important que tous les disques soient chiffrés. Toutes les versions récentes de Windows proposent la solution Bitlocker, qui permet de chiffrer les disques de manière extrêmement simple. Si un jour un poste de travail est perdu ou volé, l’attaquant ne pourra pas extraire des informations sensibles ou personnelles du disque du poste. Le pare-feu doit être paramétré pour limiter au minimum les flux entrants et sortants. Il doit compléter le cloisonnement du réseau dont nous avons parlé précédemment. Il n’y a pas vraiment de limites au durcissement d’un poste ou d’un serveur. Pour vous donner quelques autres points que vous pourrez creuser :
- évitez absolument que vos utilisateurs soient administrateurs de leur poste ;
- ajoutez un mot de passe BIOS pour que les paramètres BIOS ne puissent pas être modifiés ;
- assurez-vous que la séquence de démarrage commence par votre disque dur et non un support amovible, afin d’empêcher le démarrage sur un OS non maîtrisé ;
- activez l’UAC (User Account Control) pour vous prémunir de certaines techniques de pass-the-hash, et d’autres éléments que nous verrons ensemble dans les chapitres suivants.
Cette liste n’est pas exhaustive, il faudrait un cours entier pour parler du durcissement des postes ! Pour aller plus loin, vous pouvez aller consulter le guide de l’ANSSI dédié à ce sujet, ou le site de Microsoft.
II - Sécurisez votre Active Directory
1 - Nettoyez votre AD
Vous avez vu que dans un Active Directory, il peut y avoir des milliers d’objets, et des millions de droits entre ces objets. C’est très difficile de maîtriser tous ces éléments. En plus, avec le temps, un système d’information a tendance à se complexifier ; de nouveaux utilisateurs, groupes ou ordinateurs sont ajoutés, mais ceux qui sont obsolètes sont rarement supprimés. Il est donc temps de faire un nettoyage de printemps dans votre Active Directory ! Dans un premier temps, il peut être utile de faire la liste des objets qui n’ont pas été utilisés depuis longtemps. Il y a fort à parier que ce sont des objets qui ne servent plus, et qui peuvent être supprimés. Cela vous permettra de réduire la surface d’attaque disponible pour un attaquant. Pour identifier ces comptes, vous pouvez utiliser les résultats récoltés par BloodHound. En effet, l’outil a enregistré l’ensemble des objets d’intérêt dans une base de données Neo4J. En écrivant des requêtes pour cette base, vous pourrez extraire les informations qui vous intéressent. Par exemple, pour récolter les utilisateurs ou ordinateurs de votre Active Directory qui ne se sont pas connectés depuis plus d’un an, la requête suivante peut être utilisée :
MATCH (n {enabled:true}) WHERE ((n:User) OR (n:Computer)) AND n.lastlogontimestamp < (datetime().epochseconds - (365 * 86400)) AND n.lastlogon < (datetime().epochseconds - (365 * 86400)) and NOT (n.lastlogontimestamp IN [-1.0, 0.0] AND n.lastlogon IN [-1.0, 0.0]) RETURN DISTINCT n.name AS Name, CASE WHEN n.lastlogontimestamp > n.lastlogon THEN DATETIME({epochseconds: ToInteger(n.lastlogontimestamp)}) ELSE DATETIME({epochseconds: ToInteger(n.lastlogon)}) END AS LastUsed
Comptes qui ne se sont pas connectés depuis 2 jours
Vous pouvez également utiliser BloodHound pour identifier et supprimer des droits qui permettent de prendre la main sur le domaine. Vous pouvez par exemple utiliser la requête affichant les chemins les plus courts pour compromettre le domaine, et en fonction des résultats, vous verrez si ce sont des chemins que vous aviez anticipés, ou non. Tous les droits que vous identifiez comme non nécessaires doivent être supprimés. Il en va de même pour les comptes de service. Vous avez vu que le Kerberoasting était une attaque très puissante, permettant de prendre la main sur des comptes qui peuvent avoir des privilèges élevés. Il est donc important d’identifier ces comptes, et de les remplacer soit par des comptes machine, soit par des gMSA (Group Managed Service Account). Les gMSA sont des comptes un peu hybrides. Ils sont comme des utilisateurs classiques, mais leur mot de passe est long et complexe, et est automatiquement changé régulièrement. La documentation de Microsoft permet de rentrer un peu plus dans le détail pour découvrir comment utiliser ces comptes. Vous aviez déjà identifié ces comptes avec l’utilitaire GetUsersSPN.py d’Impacket. Vous pouvez également utiliser la requête Neo4J suivante pour les extraire :
MATCH (n:User {enabled:true,hasspn:true}) RETURN DISTINCT n.name AS Name, n.serviceprincipalnames AS SPN
Recherche de comptes utilisateurs avec un SPN
S’il est vraiment difficile de remplacer les comptes de service en place par des gMSA ou des comptes machine, la recommandation minimale est de vous assurer que le mot de passe de ces comptes est long (au minimum 16 caractères) et complexe. Ce devra être un mot de passe enregistré dans un gestionnaire de mots de passe. Ainsi, même si un attaquant récupère un ticket de service pour ce compte, ses tentatives pour retrouver le mot de passe associé seront infructueuses. Les comptes d’administration sont les cibles de choix des attaquants. S’ils sont compromis, cela leur permet d’élever leurs privilèges au sein du domaine, et peut-être le compromettre. Vous devez donc limiter le nombre de comptes à privilèges sur votre domaine. La requête Neo4J suivante vous permet de dresser la liste de tous les utilisateurs faisant partie de groupes privilégiés. Il y a notamment les administrateurs du domaine, les administrateurs de l’entreprise, mais il existe d’autres groupes permettant d’effectuer des actions d’administration sur le domaine.
MATCH (u:User)-[:MemberOf*1..]->(g:Group {admincount:true}) RETURN u.name AS Name, COLLECT(g.name) AS Group;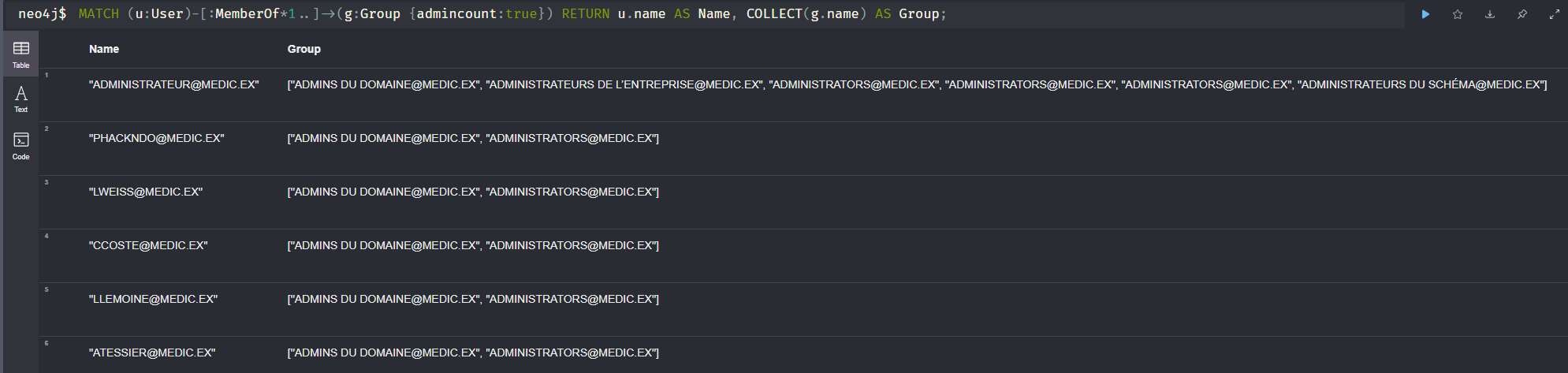
Utilisateurs membres de groupes privilégiés
Cette liste doit être réduite au strict minimum, pour réduire encore le périmètre d’attaque. Les comptes en délégation sans contrainte présentent un vrai risque, car s’ils sont compromis, il est souvent possible de rapidement compromettre le domaine. Cette délégation devrait être transformée en une délégation contrainte, en explicitant les services vers lesquels une délégation est nécessaire. La liste des points de durcissement d’un Active Directory est très longue. Les points dont nous avons parlé sont les priorités absolues, mais l’ANSSI met à disposition tout un ensemble de points de contrôle qu’il est très intéressant de lire et d’appliquer pour sécuriser un Active Directory.
2 - Sécurisez vos mots de passe
La politique de mot de passe joue un rôle essentiel dans la sécurité d’un environnement Active Directory. Vous devez vous assurer que celle-ci est bien paramétrée, pour éviter que des attaques de type password spraying soient efficaces. Vous savez récupérer cette politique grâce à la première partie de ce cours, en utilisant Get-ADDefaultDomainPasswordPolicy. Ainsi, assurez-vous que les mots de passe aient au moins 12 caractères, que la complexité des mots de passe soit requise, et qu’au bout d’un certain nombre de tentatives, le compte soit temporairement bloqué. Il est courant de voir comme paramétrage 3 tentatives échouées sur une fenêtre de 30 minutes avant que le compte ne soit bloqué pendant 30 minutes. Vous pouvez également faire un audit régulier des mots de passe. Cela signifie que les hashs NT des utilisateurs sont extraits des contrôleurs de domaine, et qu’une tentative de casser ces hashs est lancée pendant quelques heures. Les mots de passe retrouvés sont considérés comme faibles, et doivent être changés. Vous pourrez ainsi affiner votre politique de mot de passe, et peut-être également sensibiliser les collaborateurs à ce que leur mot de passe soit robuste. Enfin, sachez que si vous êtes en environnement hybride, c'est-à-dire avec un Active Directory interne et Azure Active Directory, vous pouvez profiter des fonctionnalités de protection des mots de passe d’Azure en interne. Les informations complètes sont disponibles sur le site de Microsoft dans la documentation officielle :
https://docs.microsoft.com/en-us/azure/active-directory/authentication/concept-password-ban-bad https://docs.microsoft.com/en-us/azure/active-directory/authentication/howto-password-ban-bad-on-premises-deploy https://docs.microsoft.com/en-us/azure/active-directory/authentication/howto-password-ban-bad-on-premises-operations https://docs.microsoft.com/en-us/azure/active-directory/authentication/howto-password-ban-bad-on-premises-monitor3 - Durcissez les protocoles
Les attaques sur les protocoles peuvent être souvent évitées en paramétrant correctement les clients et les serveurs. La signature des flux permet par exemple de se protéger des attaques par relais. La signature SMB est disponible sur toutes les versions de Windows, mais n’est requise par défaut que sur les contrôleurs de domaine. Faire en sorte que tous les flux SMB soient obligatoirement signés vous permettra de vous prémunir des attaques où une personne se place en position d’homme du milieu, notamment le relais NTLM lorsque le relais se fait via SMB. Un article de Microsoft est dédié à ce sujet. Il indique comment paramétrer la signature en modifiant des clés de registre, ou par GPO. Faites bien attention à la terminologie de Microsoft. Les flux SMB seront signés seulement si le client ou le serveur requiert (Required) la signature. En revanche, si la signature n’est qu’activée (enabled) pour le client et le serveur, les flux ne seront pas signés. Il est donc important que les serveurs de votre système d’information requièrent la signature des flux SMB. De la même manière, il est possible de requérir la signature LDAP sur les contrôleurs de domaine. Cela peut également être paramétré via GPO. Concernant NTLM, je vous avais rapidement dit qu’il y avait deux versions du protocole, NTLMv1 et NTLMv2. Sachez que la première version est obsolète, et n’est en aucun cas sécurisée. Il est très important de vous assurer que c’est bien la version 2 du protocole qui est en place. C’est le cas par défaut, mais pour vous en assurer, vous pouvez vérifier cette clé de registre sur les contrôleurs de domaine :
HKLM\System\CurrentControlSet\Control\Lsa\LmCompatibilityLevelSi la valeur présente ici est 0, 1 ou 2, alors NTLMv1 peut être utilisé en se connectant sur un contrôleur de domaine, ce qui présente un vrai risque. Les différents niveaux de cette clé sont détaillés dans un article de Microsoft, ainsi il faut absolument que cette valeur soit 3 ou plus. Vous pouvez également modifier ce paramètre par GPO. Enfin, les protocoles NBT-NS et LLMNR sont très dangereux s’ils sont activés. Ils permettent à un attaquant de se positionner en homme du milieu pour soit relayer une authentification, soit tenter de casser les mots de passe des utilisateurs. Les désactiver sur les postes vous permettra de vous protéger de ces attaques. Pour désactiver LLMNR, il suffit d’activer le paramètre Désactiver la résolution de noms multidiffusion accessible ici : Configuration ordinateur > Modèles d'administration > Réseau et Client DNS Pour NBT-NS, c’est moins simple. Il n’y a pas de GPO permettant de le faire simplement. Vous pouvez en revanche faire en sorte que ce script soit exécuté au démarrage des machines. Il récupérera les interfaces réseau sur les postes et désactivera Netbios :
# Récupération des cartes réseau
$regkey = "HKLM:SYSTEM\CurrentControlSet\services\NetBT\Parameters\Interfaces"
# Désactivation de Netbios sur chacune des cartes
Get-ChildItem $regkey |foreach { Set-ItemProperty -Path "$regkey\$($_.pschildname)" -Name NetbiosOptions -Value 2 -Verbose}Faites tout de même attention lorsque vous durcissez les protocoles. Il se peut que des applications installées dans le parc ne supportent pas les dernières mesures de sécurité (signature/chiffrement des flux, par exemple), et qu’elles ne fonctionnent plus après la mise en place de ces mesures.
III - Implémentez un modèle d’administration robuste
Mettre en place un modèle d’administration robuste permet de limiter les actions possibles d’un attaquant. Le modèle d’administration en tiers, ou en silos, est particulièrement efficace. Dans la partie précédente, nous avons vu que le processus LSASS enregistre tous les identifiants des utilisateurs sur la machine. Imaginons qu’un compte à haut privilège, comme un compte admin du domaine, se connecte à un poste de travail. Ses identifiants sont enregistrés dans le processus LSASS de ce poste. Il suffit alors qu’un autre poste de travail soit compromis, pour que l’attaquant vole le compte admin du poste et le réplique sur les autres machines du domaine. L’attaquant peut notamment compromettre le poste sur lequel l’admin de domaine s’est connecté, et extraire ses identifiants dans LSASS. Tout le domaine est alors compromis, l’objectif de l’attaquant est atteint.
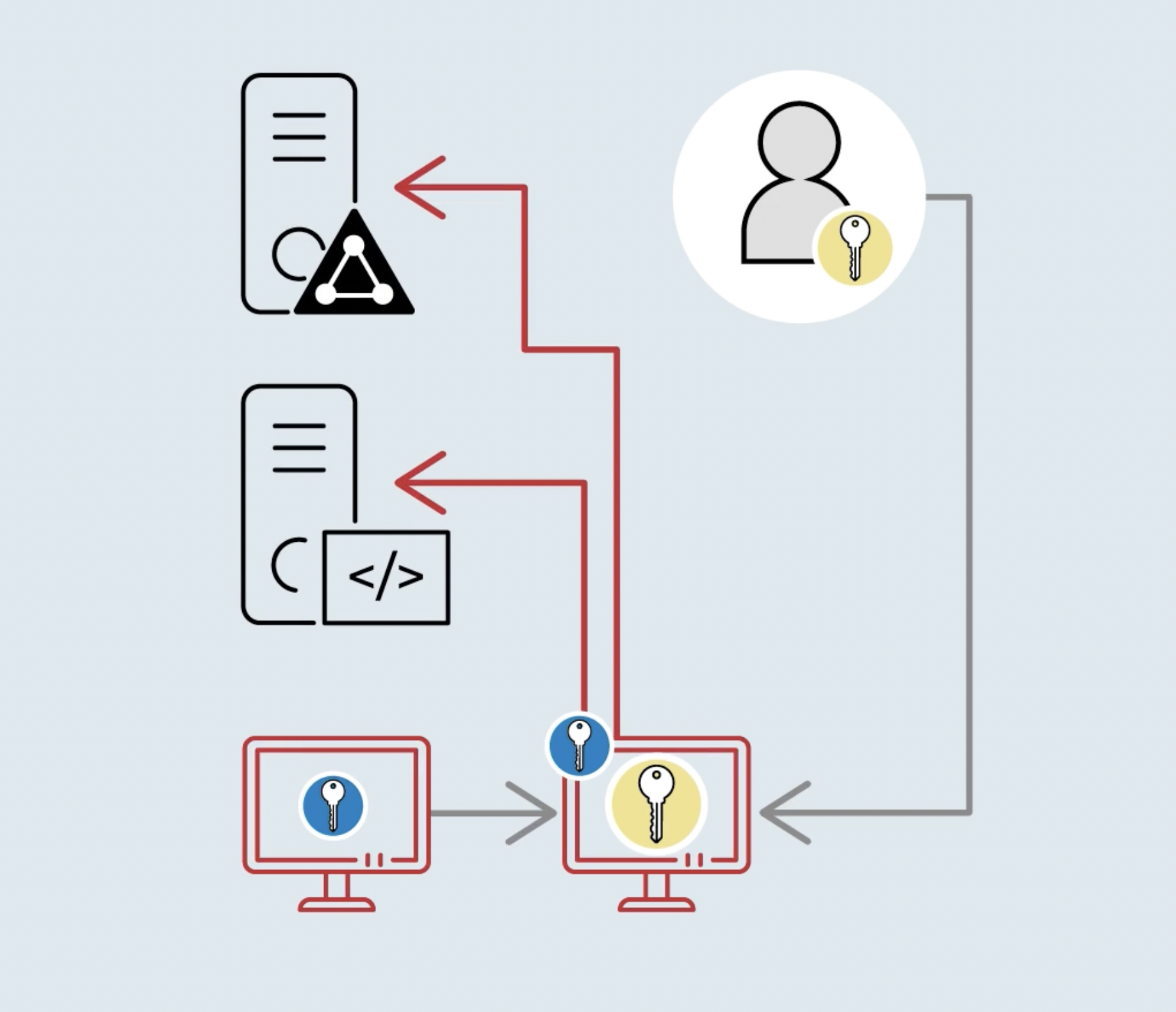
C’est pour se protéger de ce type d’attaque que le modèle d’administration en silos existe. On l’appelle aussi administration en tiers. Le principe est de définir plusieurs niveaux de criticité ou silos. On sépare les taches d’administration entre ces silos pour les rendre étanches. En cybersécurité, on définit le plus souvent 3 silos (ou 3 tiers) :
- Les postes de travail (dans lequel on retrouve l’ensemble des postes des collaborateurs – c’est le niveau de criticité le plus faible)
- Les serveurs (contenant tous les serveurs applicatifs)
- Les serveurs critiques (ce sont les serveurs, que s’ils sont compromis, permettent de prendre la main sur tout le domaine. On y trouve par exemple, les contrôleurs de domaine, les serveurs exchange ou les serveurs AD connect – ceux qui font le lien avec Azure Active Directory)
Une fois ces niveaux de criticité établi, il faut créer un compte d’administration bien distinct pour chacun de ces silos. Aucun de ces comptes ne peut alors se connecter sur la machine d’un autre silo. L’administration en silo ou en tier, permet ainsi de limiter les risques d’élévation de privilèges d’un attaquant d’une zone de criticité à une autre.
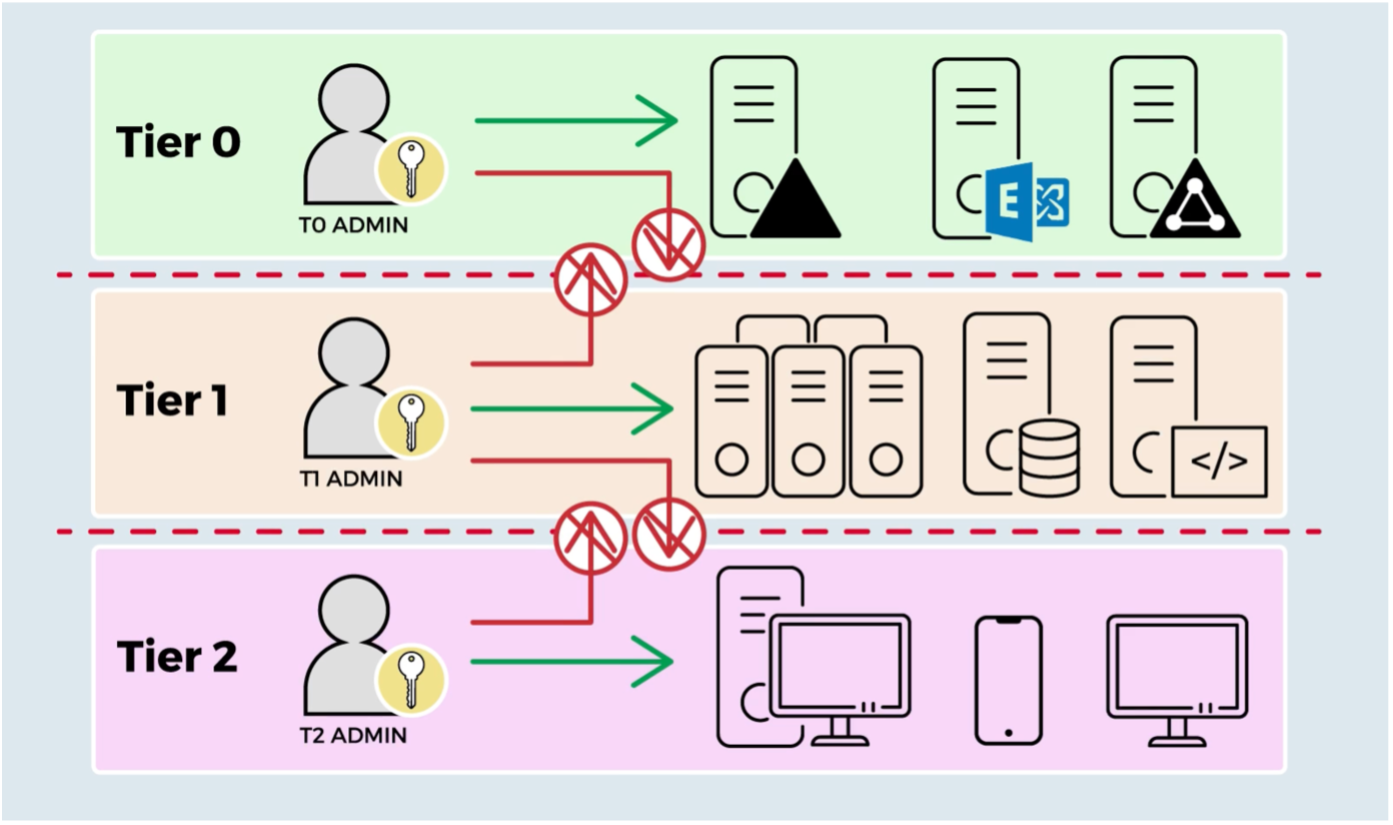
En complément de ce modèle d’administration, plusieurs actions peuvent être menées.
1 - Protected Users
Le groupe Protected Users est un groupe spécialement conçu pour protéger les comptes à privilèges. Il fait partie intégrante d’Active Directory, mais est vide par défaut. Lorsque vous ajoutez des comptes à ce groupe, des règles de sécurité vont automatiquement s’appliquer. Par exemple, les comptes en Protected Users ne peuvent plus s’authentifier via NTLM, mais seulement avec Kerberos. Cela permet d’éviter que le hash NT des administrateurs soit enregistré dans les processus Lsass des machines. Pour que Kerberos fonctionne lorsque vous vous connectez à des machines, il faut impérativement utiliser le nom de la machine, et non son adresse IP. Le principe de ticket ne marchera pas si vous utilisez des adresses IP. Donc si vous utilisez un compte Protected Users pour vous connecter à une machine via RDP ou un partage réseau, vous devrez obligatoirement renseigner le nom de la machine. Par ailleurs, ces comptes ne peuvent pas être utilisés pour de la délégation Kerberos et la durée de vie de leur TGT est réduite (4h). Ces points peuvent vous intéresser mais sachez que cette liste de durcissements n’est pas exhaustive. C’est donc une très bonne pratique que de mettre vos comptes d’administration dans ce groupe. Un des durcissements de ce groupe est que les identifiants des membres ne seront jamais enregistrés sur les machines. C’est un bon point de sécurité, mais ces comptes ne pourront jamais se connecter sur un serveur ou une machine sans connexion à un contrôleur de domaine. Donc ne mettez pas tous vos utilisateurs dans ce groupe, sinon ils ne pourront plus travailler sur leur poste en dehors de l’entreprise !
2 - LAPS
Vous vous souvenez de ma compromission de domaine lors de mon premier audit ? J’avais rejoué le hash d’un administrateur local d’un poste sur les autres postes. Ça, c’était possible parce que ce mot de passe local était partagé entre tous les postes. Pour répondre à ce problème, Microsoft propose gratuitement un utilitaire qui s’appelle LAPS (Local Administrator Password Solution). Il permet de laisser chaque machine gérer le mot de passe de son administrateur local, et d’indiquer au contrôleur de domaine le mot de passe courant. Ainsi, chaque poste a un administrateur local différent, et la technique du pass-the-hash devient d’un coup beaucoup moins pratique. Un article écrit par Login Sécurité décrit en détail le fonctionnement de cet utilitaire. Mais sachez que depuis le build 25145 de Windows 11, LAPS est intégré nativement à Windows. Plus besoin d’installer l’agent sur les postes !
3 - PPL et Credential Guard
Les identifiants des utilisateurs sont enregistrés dans Lsass lorsque ceux-ci se connectent. Un attaquant peut alors tenter de les extraire s’il a compromis le poste. Mais il est possible de limiter la casse en utilisant des protections proposées par Microsoft. La première s’appelle PPL (Protected Process Light), et lorsqu’elle est activée, elle rend l’extraction de mots de passe dans Lsass beaucoup plus compliquée. Il existe des solutions de contournement, mais c’est une première étape, et c’est applicable à toutes les versions de Windows. Vous pouvez vous référer à la documentation de Microsoft pour sa mise en place. Sur les versions plus récentes de Windows, la fonctionnalité Credential Guard permet de nettement améliorer la protection des informations stockées dans Lsass. Elles sont enregistrées dans une zone mémoire protégée, et personne ne peut y accéder directement, comme le font tous les outils actuels. Cette protection peut être activée en suivant la documentation Microsoft.
4 - PAW (Privileged Access Workstations)
Dans le modèle d’administration en tiers, les actions d’administration devraient être effectuées depuis un poste spécifique à l’administration, différent du poste de travail de tous les jours. Ce poste est appelé PAW (Privileged Access Workstations). C’est un poste qui doit être extrêmement durci pour qu’il soit le plus difficile possible à attaquer :
- il ne doit pas être connecté à internet ;
- il doit avoir le moins de logiciels possible installés dessus ;
- il doit être exclusivement utilisé pour les tâches d’administration d’un tiers (postes de travail, ou serveurs, ou serveurs critiques, par exemple). Il faut donc au minimum une PAW par tiers, et par administrateur ;
- une authentification multifacteur devrait être implémentée pour se connecter sur cette machine.
L’idéal serait que cette PAW soit une machine physique dédiée. Une machine virtuelle peut être envisagée, mais ne présente pas le même niveau de sécurité.
IV - Surveillez votre système d’information
1 - Surveillez l’état du parc informatique
Vous avez mis à jour vos systèmes et applications, évitant ainsi qu’un attaquant puisse exploiter une vulnérabilité sur un composant obsolète, et c’est un premier pas. Il est également nécessaire de surveiller de près votre parc, vos machines. Vous pouvez utiliser des outils qui analysent en continu et en temps réel :
- les versions des systèmes d’exploitation ;
- la liste des applications installées sur les systèmes, et leur version ;
- la présence et le statut de l’antivirus ou EDR ;
- la configuration du pare-feu.
Toutes ces informations vous permettront de détecter des écarts s’ils surviennent. Par exemple, si soudain l’antivirus de l’un des postes est désactivé, ce n’est pas un comportement attendu, et il mérite une attention particulière. De la même manière, si vous découvrez que le port 4444, port par défaut dans de nombreuses attaques, a été autorisé en sortie sur un de vos serveurs, il s’agit très probablement d’un comportement malveillant. Sachez que si vous avez aussi une flotte d’appareils mobiles, vous pouvez également surveiller les applications installées et les niveaux de mise à jour. Vous pouvez passer par un outil de type MDM (Mobile Device Management) pour gérer vos équipements mobiles. En plus de la surveillance de ce qui est installé et configuré sur les postes, pouvoir détecter ce qu’il s’y passe est également un vrai atout pour anticiper des attaques. Un EDR permet de faire ce travail, et peut le faire de manière très efficace lorsqu’il est bien configuré. Par exemple, si un attaquant tente une attaque de type ransomware (ou rançongiciel), il essaiera de chiffrer un grand nombre de fichiers sur le poste. L’utilisateur devra payer une rançon pour, peut-être, les déchiffrer. Un EDR est tout à fait en mesure de détecter ce type de comportement. Il n’est pas courant qu’un processus modifie des centaines de fichiers en un temps court. Vous pouvez donc décider d’un seuil à partir duquel ce comportement doit être signalé, et potentiellement bloquer le processus à l’origine de ces modifications.
2 - Surveillez les chemins de contrôle
Maintenant que vos machines sont sous contrôle, la même logique doit être appliquée à votre environnement Active Directory. Vous avez nettoyé les utilisateurs, groupes, machines, privilèges qui n’étaient pas nécessaires, et il faudra surveiller que votre nouvel environnement reste sain. Vous voudrez donc identifier les modifications apportées à l’Active Directory qui pourraient avoir des conséquences d’un point de vue sécurité. Voici quelques exemples :
- ajout d’un nouvel administrateur de domaine ;
- ajout de délégation non contrainte sur un poste ;
- ajout de droits privilégiés pour un utilisateur ;
- modification des droits sur une GPO ;
- utilisation d’un compte brise-glace ;
- etc.
Vous pouvez régulièrement lancer une collecte BloodHound et confronter les résultats, mais ce n’est pas optimal sur le long terme. La version BloodHound Entreprise permet en revanche d’analyser en temps réel et en continu les modifications apportées, et identifie les nouveaux chemins de compromission apportés par ces modifications. D’autres outils, complémentaires, peuvent vous apporter des éléments de suivi. Je vous ai très rapidement parlé de l’outil PingCastle, et c’est un excellent moyen de mesurer l’état de santé de votre environnement Active Directory. Cet outil vérifiera beaucoup de points de contrôle, en suivant dès que possible les points de contrôle publiés par l’ANSSI. Une note sera alors attribuée au niveau de sécurité de l’Active Directory. En lançant cet outil régulièrement, vous pourrez avoir un suivi des points de contrôle et des écarts qui peuvent survenir, pour les traiter au plus vite. Un exemple de rapport est disponible sur le site internet de PingCastle. Il existe aussi l’outil ORADAD de l’ANSSI, qui permet de récolter les informations nécessaires sur l’Active Directory, pour vérifier les points de contrôle qu’elle a publiés. Vous pouvez également vous tourner vers Tenable.AD, qui permet d’avoir une vision en temps réel de la sécurité de votre environnement Active Directory, et qui propose des remédiations pour améliorer le niveau de sécurité en continu.
3 - Identifiez les événements d’intérêt
Le journal d’événements Windows est une mine d’informations pour celui qui souhaite surveiller un ou plusieurs postes Windows. Tout, ou presque, peut être récolté et analysé pour identifier des comportements malveillants. La liste des journaux d'événements est dressée et détaillée par Microsoft. Bon le problème c’est que les journaux d’événements Windows, il y en a des milliers ! C’est vrai, tout comme dans la phase de reconnaissance, vous pourriez crouler sous le nombre d’événements journalisés par le système d’exploitation et les différentes applications. Mais rassurez-vous, vous pouvez faire le tri et commencer par analyser des journaux et catégories d’événements essentiels. Vous pourrez enrichir votre détection après ça. Les événements qu’il faut absolument surveiller sont listés par Microsoft dans un appendix, et permettent par exemple de détecter tous les exemples de modifications que je vous ai listés dans la section précédente. Mais ils permettent d’aller plus loin, notamment en surveillant les tentatives de connexion pour détecter les attaques comme le password spraying, ou en détectant la création ou la modification de services ou tâches planifiées, ce qui permet d’identifier des tentatives de mouvement latéral ou de persistance. S’il y a des événements qui ne sont pas clairs pour vous, sachez que le site Ultimate Windows Security les recense et les décrit en détail. L’outil Sysmon peut également être utilisé pour aller plus loin dans la collecte d’événements Windows. Microsoft a par ailleurs rédigé un guide d’une centaine de pages intitulé Recommandations de sécurité pour la journalisation des systèmes Microsoft Windows en environnement Active Directory, qui vous permettra d’aller plus loin et plus finement dans votre stratégie d’audit d’événements Windows. Il n’y a pas que Windows qui journalise des événements. Les équipements et applications déployés sur le parc permettent généralement de récolter ce qu’il se passe. Que vous ayez des pare-feu, des sondes réseau, un EDR ou des équipements de sécurité, tous les événements émis peuvent être bons à prendre pour tenter de mieux détecter une intrusion sur le système. Comment on s’en sort pour traiter et analyser tous ces événements ? Je ne vais quand même pas me connecter sur toutes les machines et tous les serveurs pour récolter les événements et faire des recherches à la main ? Non en effet, et c’est bien là le nerf de la guerre pour la défense d’une entreprise. Il est indispensable d’identifier les événements qui vous intéressent, mais ce n’est pas suffisant. Il faut être capable de leur donner de la valeur pour pouvoir agir en conséquence.
4 - Donnez de la valeur aux événements
Tous les événements que vous avez identifiés doivent maintenant être centralisés pour pouvoir être analysés. Cela peut être fait à l’aide d’un SIEM, ou Security Information and Event Management. C’est un outil qui permet aux équipes de défense de collecter et agréger les données des journaux d’événements. Concrètement, vous faites en sorte que tous les logs qui vous intéressent arrivent dans le SIEM. Cela lui permettra de les analyser, et grâce à la corrélation de ces logs et à la mise en place de règles de détection, le SIEM peut faire sonner des alertes de sécurité qui devront être traitées par les équipes de détection. Il existe beaucoup de solutions payantes sur le marché, mais il est possible d’utiliser la solution open source ELK (Elasticsearch, Logstash, Kibana) qui répond aux besoins d’un SIEM. Mais il existe d’autres solutions pour centraliser des logs, tels que le couple Windows Event Forwarder et Windows Event Collector, développés par Microsoft, permettant de centraliser tous les événements Windows. Vous pourrez trouver plus d’informations sur la documentation de Microsoft. C’est très bien d’avoir tous les événements à un seul endroit, mais ça ne change pas le fait qu’il y a des milliers d’événements. Comment je fais pour détecter un attaquant ? C’est là qu’interviennent les règles de détection. Ces règles vont être écrites pour détecter des menaces potentielles. Maintenant que vous avez des connaissances sur les techniques d’un attaquant pour énumérer, exploiter et vous déplacer dans un système d’information, vous pourrez créer des règles qui détectent toutes ces techniques afin d’identifier les acteurs malveillants au sein de votre réseau. Par exemple, une règle de détection de password spraying peut sonner quand vous observez plus de 10 événements de type “Un compte n'a pas réussi à se connecter” (événement 4625) en moins de 10 secondes, sur des comptes différents. Comme il existe beaucoup de produits de type SIEM sur le marché, un format de signature générique et open source a été développé pour la création de règles dans un SIEM : les règles SIGMA. Elles permettent de faciliter le partage de techniques de détection, puisque c’est une syntaxe commune connue et comprise par toutes les personnes implémentant des règles. Vous pourrez trouver des exemples de règles dans le dépôt GitHub SIGMA-Detection-Rules. Tous ces outils, ces processus à mettre en place et les équipes de défense peuvent être réunis dans ce qu’on appelle un SOC, ou Security Operation Center. Je vous propose de découvrir cette notion dans la vidéo !